在深入探讨之前,先做个简要回顾:
•主成分是原始(标准化/中心化)数据的线性组合
•这些线性组合代表了数据可以投影到的直线(从而降低维度)
•数据可以投影到许多可能的直线上
•主成分的定义是通过最大化数据的方差来确定的
本节将主要聚焦于最后一点。请看下图。该图展示了一个三维对象的二维投影。仅凭这些信息,可能很难判断该投影所代表的对象是什么。在讨论完主成分的定义后,我们将重新审视这个问题。

如前几节所述,PCA 是一种在尽可能保留数据信息的同时降低数据集维度的技术。数据中的“信息”由方差来体现。设想一个变量,其所有观测值的数值完全相同。该变量的方差为零,因此无法利用该变量来区分不同的观测值。 变异性更大的变量对PCA而言包含更多“信息”。只需确保数据经过适当转换(通常通过标准化),以免不同量纲测量的变量仅因其计量单位而占据主导地位。
因此,PCA的首要目标是尽可能保留更多的“信息”(方差)。另一个主要目标是确保新变量能够用于尽可能精确地“重建”原始数据。请记住,将数据投影到低维空间会导致部分信息丢失,因此无法从低维空间完美重建原始数据。 然而,我们探讨了多种方法来最小化投影产生的误差。最重要的是,我们发现通过最小化数据点与直线之间的垂直距离所获得的最佳拟合直线,能够同时实现这两个目标。在PCA中,这条最佳拟合直线就是第一主成分。
以下是上一节中的两幅图表,展示了如何同时实现最小化数据与拟合线之间的距离以及最大化投影点在该线上的方差。左侧是一条在最小化距离和最大化方差方面表现不佳的直线。右侧的图表则展示了满足这些目标的最佳拟合线。
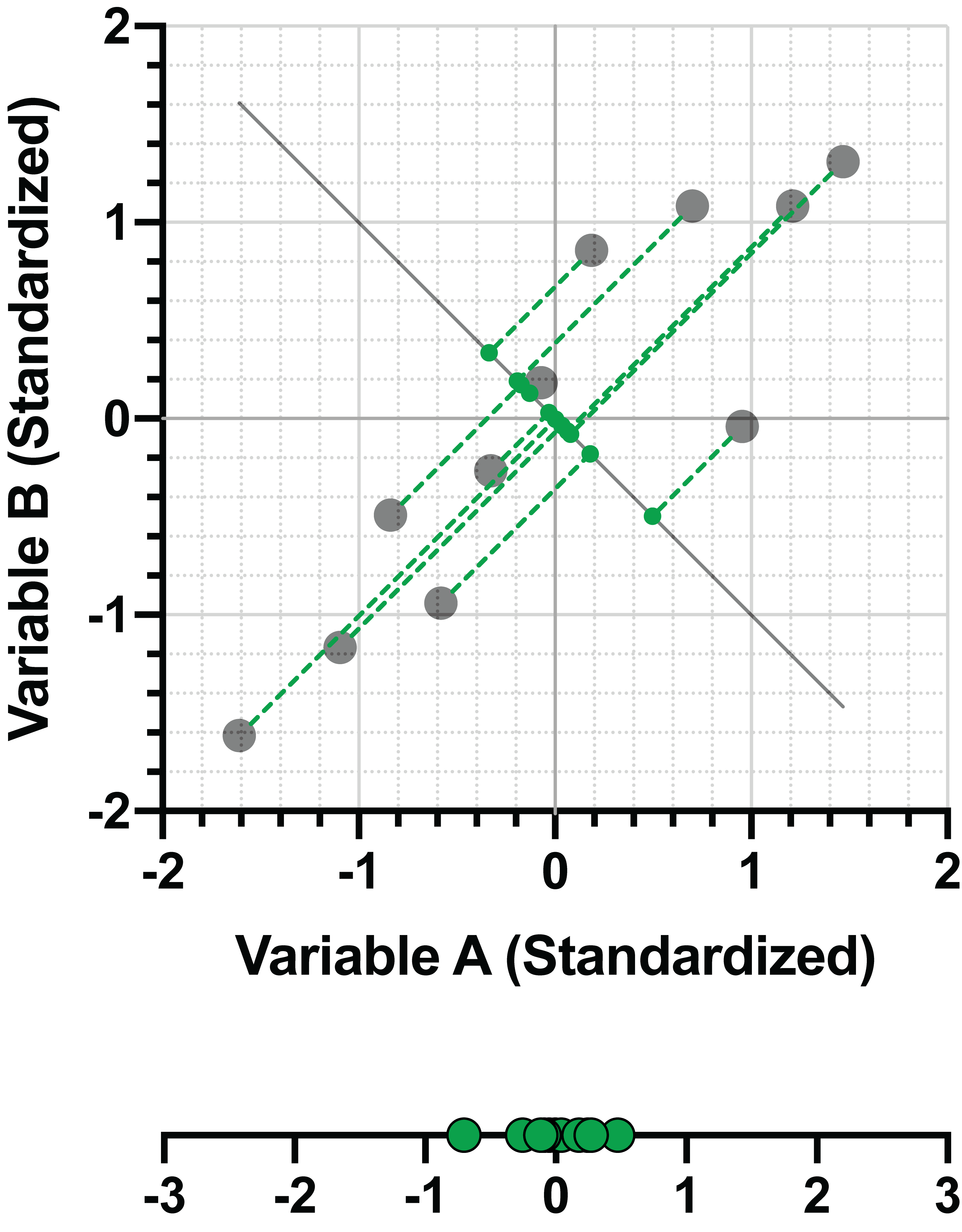
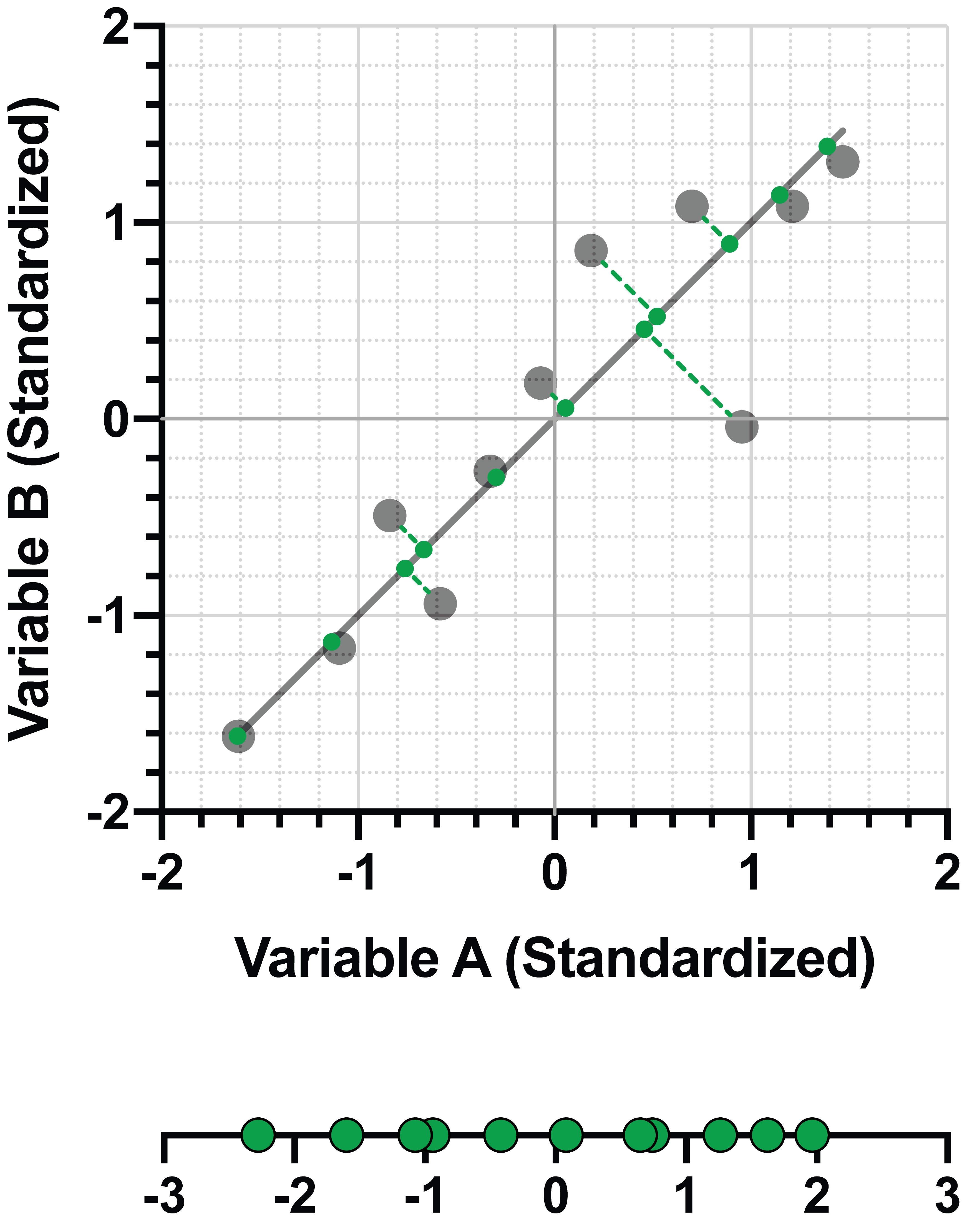
在上例的右侧面板中,该直线(我们将其称为 PC1,即“第一主成分”)可以表示为两个(标准化)变量的线性组合。对于本示例:
PC1 = 0.707*(变量 A) + 0.707*(变量 B)
进阶说明:该线性组合的系数可以矩阵形式表示,在此形式下被称为“特征向量”。该矩阵通常作为PCA结果的一部分呈现
借助该公式,我们现在可以通过较少的变量(本例中仅从两个变量减少到一个)来近似(“重建”)原始数据。下表展示了将变量A和B的值代入该方程后得到的结果:
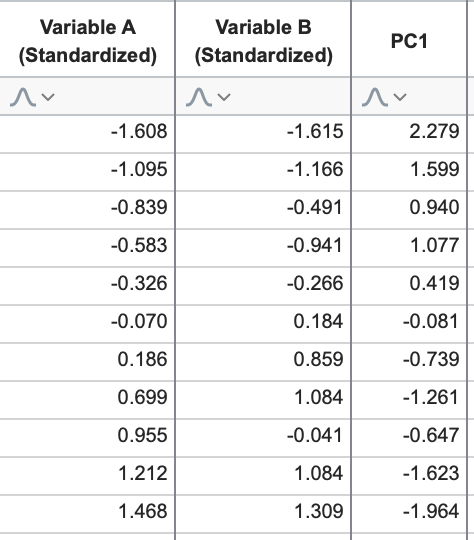
这些关于PC1的数值被称为PC1的“得分”,代表了投影数据在该主成分上的位置(参见上图右侧的数轴,并将其与第三列中的数值进行对比)。
本示例使用了一个仅含两个变量的简单数据集。由于PCA的目标是降维,我们仅寻找了第一个主成分。但在下一节中,我们将讨论如何定义其他主成分。
最后一点。我们现在知道,主成分是通过最大化投影中数据的方差来定义的。为了进一步说明这一点,请看下图:

这是之前展示的同一 3D 对象的另一种 2D 投影,现在应该很清楚我们看到的是什么了。如果我们将鲨鱼身体的长度视为 X 轴,高度视为 Y 轴,宽度视为 Z 轴,那么这张图展示了鲨鱼在 XY 平面上的投影。 之前的(信息量较少的)投影是将同一条鲨鱼投影到YZ平面上。之所以说第二个投影“信息量更大”,是因为数据的大部分变异性都集中在X方向!我们能从这个“侧视图”中获取更多信息,因为它保留了原始数据更多的变异性,这与主成分(PCs)的定义原理一致。
然而,尽管在数据投影方面,“正面视图”可能信息量较少,但对于您应该以多快的速度游泳,这种视角却提供了远更丰富的信息……