Cox比例风险回归的目标是建立一个模型,用于估计某一人群中特定事件发生的风险率。该人群由多种不同的预测变量定义,这些变量在模型中用于估计该风险率。基于该风险率,可以估计研究人群的生存函数。 进行Cox比例风险回归时存在诸多假设,在进行此项分析时,您应了解这些假设。在本页面中,您将找到在进行Cox比例风险回归或解释结果时需要考虑的一些重要问题。
 各组的危险率函数是否成比例?
各组的危险率函数是否成比例?
鉴于该分析的名称,首先确认“比例风险”这一假设是否成立是合乎逻辑的。该假设本质上表明,存在一个且仅有一个适用于所有观测值总体的基础风险函数。 任何特定个体(或个体群体)的危险率,仅仅是该基线危险函数的缩放版本。对该基线危险函数应用的缩放程度,取决于模型中该个体(或群体)预测变量的数值。如果比例风险假设成立,那么在某个时间点危险率为基线危险率3倍的个体,在所有时间点的危险率都将是基线危险率的3倍。 这也意味着,任意两个个体或群体之间的风险比在所有时间点都必须保持恒定。如果男性的风险比是女性的2.5倍,这意味着男性在所有时间点发生目标事件的风险比都是女性的2.5倍。这是一个相当强烈的假设,鉴于生物系统的复杂性和变异性,它未必总是严格成立。 为检验这一假设,可绘制对数减对数图(在Prism软件中,通过Cox回归参数对话框的“残差”选项卡生成此类图表)。
如果比例风险假设被违反,可以采用一些方法来尝试处理这一问题。 一种常见方法是利用违反比例风险假设的变量对模型进行分层。一旦确定了相关变量,输入数据将根据该变量的水平被划分为新的组别。随后,分别对每个新组别拟合Cox比例风险回归模型。这一过程有时被称为拟合“分层Cox模型”。然而,Prism并未提供自动执行此操作的选项。
数据组织是否正确?
要在 Prism 中进行 Cox比例风险回归,必须将数据输入到多变量数据表中。在此表中,每列代表一个变量,每行代表一个观测值。对于每个观测值(行),必须输入以下内容:
•事件发生时间(响应)变量
•事件/删剪(结果)指示变量
•模型中包含的每个预测变量
如果某行存在上述任何一个变量的缺失值,在拟合模型时该行将被忽略。请注意,缺少事件/删剪变量值的观测值(行)不会用于拟合模型,但在模型拟合完成后,仍可用于通过参数对话框中的“预测”选项卡计算估计生存概率(前提是该观测值提供了事件发生时间变量的值)。
我的 Cox比例风险回归模型应该包含截距项吗?
不需要!与多元线性回归不同,Cox比例风险回归中不存在截距项。此处的数学依据在此不作展示,但一般解释是:由于基线风险 (h0(t)) 未定义,模型中添加的任何常数截距项都会被该基线风险“吸收”。因此,在定义 Cox比例风险回归模型时,既不需要(也不允许)截距项。
删剪是否属于非信息性删剪?
在生存分析中,部分观测值或个体被删剪,这意味着我们无法获得其经历目标事件前已过去的时间信息(我们仅掌握其被删剪前已过去的时间信息)。 然而,Cox回归(以及其他形式的生存分析)所做出的一个假设是:观测值的删剪与个体死亡(发生目标事件)的概率之间不存在关联。 删剪的观测值发生目标事件的概率不应更高(或更低)。换言之,这一假设表明:如果删剪的观测值实际上被随访至发生目标事件,其生存时间分布将与未被删剪观测值的生存时间分布相同。
非信息性删剪还意味着,观测值被删剪的原因不应与研究设计相关。以一项研究实验性药物的临床研究为例。该药物的疗效可能非常显著,以致于治疗组中的个体可能认为自己已“痊愈”,不再需要随访(导致这些个体被删剪)。 而对照组受试者则不会出现这种改善,因此会继续参与研究。由于治疗组的截断率远高于对照组,治疗组的实际生存时间可能无法准确记录,从而导致治疗效果无法被发现。此外,治疗不应导致患者感觉不适到选择退出研究(这种情况也不被视为非信息性删剪)。
每个观测值的生存时间是否相互独立?
与许多回归技术一样,一个重要假设是观测值彼此独立。在Cox回归中,每个个体的生存时间必须相互独立。换言之,个体1的生存时间不应依赖于个体2的生存时间。
(连续型)预测变量与对数风险率之间是否呈线性关系?
Cox比例风险回归模型的另一个假设是:预测变量的效应与对数风险呈线性关系。这句话乍听可能令人困惑,但请考虑Cox回归中用于计算风险率(h(t))的方程:
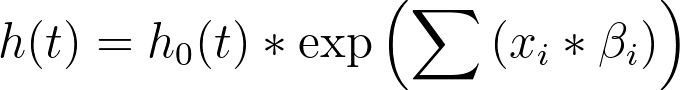
经过一些变换和简化,该方程可写为如下形式:
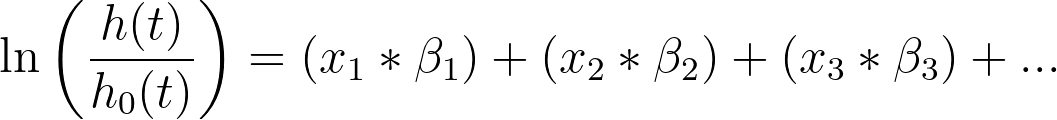
在此形式下,更容易看出预测变量(x1、x2、x3 等)被假设对对数风险具有线性影响。 有几种方法可以检验这一假设,例如使用偏差残差并将其绘制在预测变量的数值上(该图表可通过“残差”选项卡中的选项生成)。通过该图表,我们预期残差在预测变量的数值上不会呈现任何规律(残差应均匀地集中在零点周围)。
当预测变量表现出非线性时,可采用某些方法来尝试纠正这一线性假设的违背。与其他回归技术类似,一种解决方案可能是对变量进行变换(例如使用对数或指数变换)。其他可能的方法包括在模型中加入该变量的多项式项,或将连续变量转换为分类型变量。
个体的预测变量值在时间上是否保持恒定?
Cox比例风险回归的一个有趣假设是:预测变量的值随时间推移不会发生变化。在采用Cox比例风险回归进行分析的研究中,受试者必然会被随访不同长短的时间(以便确定每位受试者发生目标事件所经历的时间)。然而,关键在于在此期间预测变量不能发生变化。 例如,若“治疗”是包含“对照组”和“治疗组”的预测变量,则研究期间个体不应在这些组之间转换(“治疗组”的个体应始终处于治疗组)。 在其他类型的多重回归(例如多元线性回归)中,数据不包含时间成分,因此无需这一假设。然而,鉴于Cox回归数据的特性,确保该假设成立至关重要。
预测变量之间是否存在线性相关性(彼此之间)?
如果模型中的预测变量存在高度多重共线性,则估计的标准误差和 P 值将失去意义。请阅读更多关于多重共线性的内容,以及 Prism 如何报告模型变量之间的这种关系。
您是否有足够的数据来确保结果的可靠性?
一般而言,在统计建模中,数据越多越好。然而,受各种限制因素影响,样本量或总体规模往往有限。表格结果页面的“数据摘要”部分包含输入数据的多项重要汇总统计量。其中,数据中的事件数、指定模型拟合的参数数以及这两者之间的比率,可用于评估数据是否“足够”支持所选模型。 虽然没有具体的数值能断言某个模型是否拥有“足够”的数据,但一般经验法则是:模型中每个拟合参数应至少对应 10 个事件。 请注意,此处指的并非观测值(包括删剪数据和事件数据)的比率,而是每个参数对应的事件数量。此外,需知该比率的分母是模型中的参数估计数,该数值可能大于变量数(因为模型中包含了具有两个以上水平的分类变量或交互作用)。
您是否存在过拟合或欠拟合?
与上述要点类似,您指定的模型是否包含过多变量(过拟合)或过少变量(欠拟合)?将指定模型拟合到数据后,可能会发现某些纳入的预测变量并未对风险率的变化产生贡献(换言之,其β系数接近或等于零,或其风险比接近或等于1)。 如果这些变量的数值对风险比的变化没有贡献,您是否还想将它们保留在模型中?在某些情况下,由于这些变量在实验设计中的重要性,或者基于您对相关实验和科学知识的理解,保留它们是必要的。而在其他情况下,或许直接将该变量从模型中移除更为合理,尽管这是一个有争议的话题,因此在未经过深思熟虑之前请勿贸然操作。
另一方面,模型的拟合优度可能不如预期。这可能是因为某个重要变量未被测量,或者您选择不将其纳入模型。在这种情况下,该模型被认为对数据“拟合不足”。如果缺失的变量是实验中未测量的,您除了重新收集更多数据外别无他法。 然而,如果缺失的变量仅仅是被从模型中省略了,您可能需要重新考虑为何移除了该变量。此外,您还可以使用参数对话框中的“模型”选项卡,将预测变量的各种转换和交互作用纳入模型中。