Cox比例风险回归的目标是估计观察人群的风险率(进而估计生存函数)。 风险函数的值不仅取决于距离目标事件发生的时间,还取决于模型中每个预测变量的取值。利用拟合模型以及模型中各预测变量的已知值,可以对特定时间点的估计生存概率进行预测。虽然这是该方法的一个强大功能,但它并非进行Cox回归的必要条件,除非需要从模型中获得具体的预测结果,否则可以忽略不计。
Cox回归的预测功能
一旦使用Cox比例风险回归拟合了模型,在给定各预测变量的数值前提下,即可估算特定时间点的风险值(及生存概率)。Prism可通过两种不同来源的信息预测风险值和生存概率:来自输入数据表中的数据点,以及“预测”选项卡中的特定数据点。
基于数据表中预测变量的值进行预测(或插值)
选中此复选框后,Prism 将检查输入数据表中满足以下条件的行:
1.包含目标事件发生前经过时间的数值
2.包含指定模型中每个预测变量的值
3.不包含结果(事件/删剪)变量的值
对于每一行,Prism 将使用确定的最佳拟合参数系数,结合数据表中该行的数值,计算出这些观测值的线性预测因子(Xβ)、风险比(exp[Xβ])以及累积生存率。 请注意,与简单线性回归或非线性回归不同,用于插值的行不必位于数据表的末尾。Prism 将搜索任何满足上述三个插值标准的行。
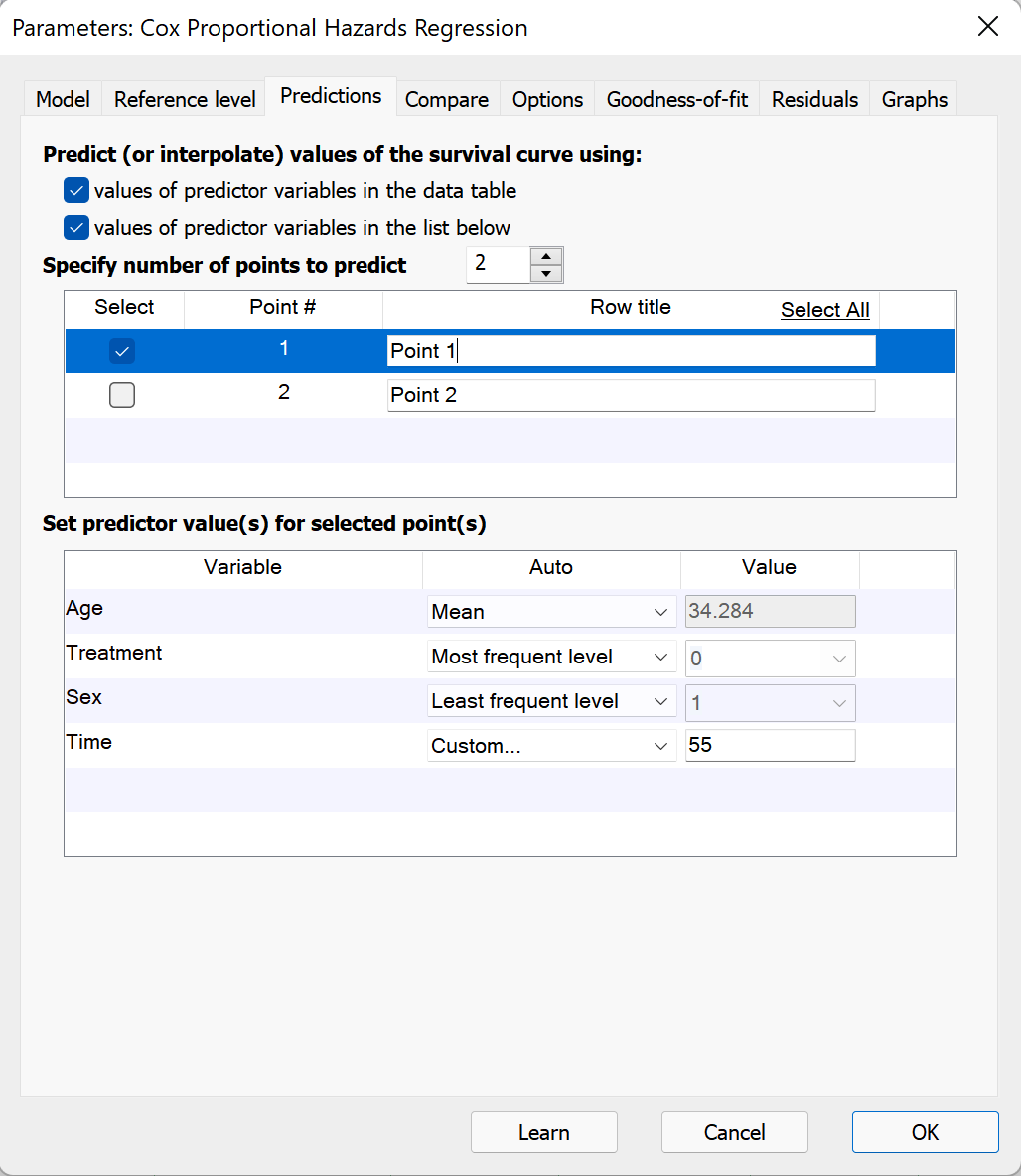
根据对话框中的预测变量值进行预测(或插值)
勾选此复选框后,Prism 允许您通过指定目标事件发生前的经过时间以及模型中每个预测变量的值,来创建用于插值(预测)的自定义点。使用上下箭头指定要添加用于插值的点数。在两个文本框的顶部,可以为每个插值点添加名称/标签。
每个插值点必须为模型中的每个预测变量定义具体数值,并且必须包含目标事件发生前的经过时间值。要指定这些数值,请选择“自动”方法或从下拉菜单中选择“自定义…”。各预测变量的默认设置如下:
•连续变量(包括“距离目标事件的经过时间”变量):“自动”下拉菜单将设置为“默认”,且值为零
•分类型变量:自动下拉菜单及其值将与该变量的参考水平设置一致。如果未手动更改参考值,则自动下拉菜单将设置为“第一水平(默认)”
由于“事件发生前经过时间”的默认值设为零,因此累积生存率的预测值为 1(假设在事件发生前经过时间为零时的预测生存率为 1 或 100%)。
对于每个预测变量,您可以输入一个值,或选择该变量的最小值、最大值或特定数值。
同样,对于分类变量,Prism 提供了使用数据中的第一层、最后一层或最/最不常见的层进行插值的选项。同样地,如果数据发生变化,Prism 将自动相应地更新插值。
最后,对于连续变量和分类变量,Prism 都允许输入“自定义…”值用于插值。
若输入数据发生变化,预测值会如何变化
当Cox比例风险回归的输入数据发生变化时,Prism将自动重新计算指定模型的回归系数。这将影响使用该模型预测的数值。此外,对于使用对话框中列出的预测变量值进行预测的点,数据的更改可能会改变各种“自动”赋值方法的数值。
对于连续变量,Prism 提供了从数据表中该变量的最小值、最大值或均值进行插值的选项(通过“自动”方法下拉菜单)。如果数据发生变化,这些最小值、最大值或均值也可能随之改变,导致插值计算中使用的数值不同。
同样地,对于分类型变量,Prism 提供了使用数据表中该变量的第一个级别、最后一个级别、最频繁级别或最不频繁级别进行插值的选项(通过“自动”方法下拉菜单)。如果数据发生变化,第一个、最后一个、最频繁或最不频繁的级别也可能随之改变,导致插值计算中使用的值发生变化。
请注意,用于插值的分类变量的默认“自动”方法(及值)将与该变量的参考水平的方法(及值)一致。但是,一旦某个点使用特异性方法进行了插值,即使更改了参考水平的确定方法,该插值点的已分配方法也不会随之改变。