在进行回归分析时,高度相关的预测变量(或更普遍地说,线性相关的预测变量)会导致估计结果不稳定。这通常意味着无法准确解读回归分析得出的估计值。原因在于,当两个预测变量存在线性依赖度时,可以用其中一个预测变量来预测另一个预测变量的值。换句话说,一个预测变量可以表示为另一个预测变量的线性函数。 例如,如果公式 X2 = 3*X1 + 6 成立,则预测变量 X1 和 X2 就是线性相关的。对于 X1 的任何给定值,X2 的值都是已知的(因此无需进行估计)。如果出现这种情况,纳入 X2 并不会为模型增添任何 X1 无法描述的新信息。
在多元回归分析中,这一问题被称为多重共线性。在极端情况下,当一个预测变量与另一个完全线性依赖时,完成分析所需的优化算法将无法确定任一列的系数估计值。这是因为这些参数估计值存在无限多种潜在解。 为阐明这一概念,本示例举例说明:假设某数据集中包含两个表示体重的变量,一个以磅为单位,另一个以千克为单位。由于这两个值存在完美的线性相关性(磅 = 2.205 × 千克),包含这两个变量的模型将无法确定其中任何一个的参数估计值。
考虑以下Cox比例风险回归的案例。假设仅有一个预测变量(x1),且该预测变量的最佳拟合参数估计值为2。Cox回归模型为:
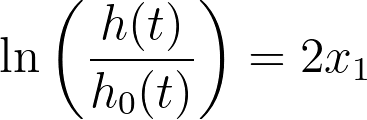
现在,假设我们添加一个新变量(x2),它是第一个预测变量的副本。已知 x1 = x2,可见以下所有方程均等同于第一个:
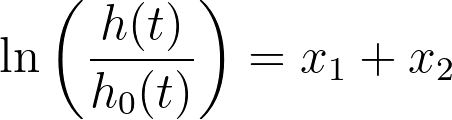
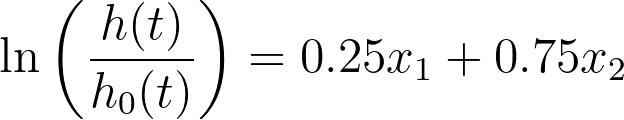

事实上,该方程可以有无限多种方式重写,使用不同的系数,但结果值始终相同。在统计学中,这种模型被称为不可识别模型。在这种极端情况下,标准误差、置信区间和P值根本无法计算。
然而,在实际应用中,预测变量之间通常并非完全线性相关,而只是存在强相关性。尽管 Prism 能够在此类情况下生成参数估计值,但多重共线性会增加参数估计的不确定性,这一问题依然存在。这体现在更宽的置信区间和更大的 P 值上。
若您仅关注利用模型根据一组已定义的预测变量值预测未来结果,那么较大的标准误差和较宽的置信区间可能并非主要问题。但若您关注参数估计量的具体数值及其解释,多重共线性便成为一个问题。
在 Prism 中,多重共线性通过方差膨胀因子 (VIF) 进行评估。一般经验法则是,VIF 值大于 10 表明存在严重的多重共线性,且很可能对模型拟合产生不利影响。 当 VIF 值达到这一程度时,通常建议移除 VIF 值较高的预测变量之一,并重新拟合模型。必要时可重复此操作。本页面提供了关于 VIF 的更详细信息。