在进行任何类型的回归分析时,人们通常会关注该模型与可拟合的其他潜在模型相比,对数据的描述效果如何。 Prism 提供了多种方法,可用于评估模型对给定数据的拟合优度。具体而言,对于 Cox比例风险回归,Prism 将报告以下指标的数值:赤池信息准则 (AIC)、偏对数似然 (LL)、偏对数似然的变换值(-2*LL)以及伪R平方。
赤池信息准则(AIC)
该值源自信息论方法,旨在评估数据与模型的拟合程度。报告的数值既依赖于部分对数似然(下文将描述),也依赖于模型中的参数数量。 请注意,由于在存在删剪数据的情况下难以确定观测值数量,Prism(与其他应用程序一样)仅报告AIC,而不报告校正后的AIC(AICc)。计算AIC所需的公式如下:
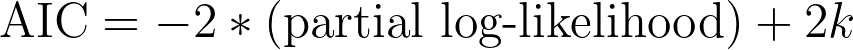
其中 k 表示模型中的参数个数(Prism 在结果的数据摘要部分中报告该数值)。
AIC的解读
AIC的解读主要依赖于模型拟合的似然度(更具体地说,是对数似然度,或在Cox回归的情况下,是偏对数似然度)这一概念。 无需深入探讨似然度的数学原理,其基本思想是:模型的似然度反映了数据与该模型的拟合程度(另一种理解方式是:假设所选模型是“真实”模型,那么这些数据由该模型生成的“可能性”有多大)。 基于此,可以理解为“优质”模型会产生较高的似然值,而“劣质”模型的似然值则较低。
在上式中,我们可以看到AIC的依赖度取决于两点:
1.模型的部分对数似然
2.模型中的参数个数 (k)
对于Cox回归模型而言,偏对数似然值即为偏似然值的对数。如前所述,数据拟合良好的模型其似然值会高于拟合不佳的模型。因此,数据拟合良好的模型的偏对数似然值也会大于拟合不佳的模型。 通过将该值乘以一个负数,我们可以发现,数据拟合效果更好的模型,其“-2*(偏对数似然值)”的数值会比数据拟合效果较差的模型更小。因此,我们可以看出,更大的似然值最终会导致更小的AIC值(忽略稍后将讨论的2k项)。所以,AIC值越小代表模型拟合效果“越好”,这合乎逻辑。
AIC 公式的第二部分是一个“惩罚”项,旨在防止过拟合(即模型中使用过多参数)。 对于任何模型,增加参数(在其他条件不变的情况下)通常都会提高模型拟合的似然值。当参数足够多时,您将能够完美地预测输入数据集中的数据(但该模型几乎肯定无法准确预测输入数据之外的未来观测值)。这就是过拟合的问题:模型对输入数据的拟合过于紧密。 AIC 公式会增加一个等于模型参数数两倍(2k)的值,因此参数更多的模型,其 AIC 值会被施加更大的“惩罚”。
结合以上信息,我们可以更深入地理解 AIC:
•在同一数据集上,AIC值较小的模型表明其拟合效果优于AIC值较大的模型
•参数较多的模型虽然似然值更大,但其AIC值也会因“惩罚项”而增加
关于AIC值需要特别注意的最后一个重要概念是:它们只能用于比较拟合于同一数据集的模型!AIC值是根据似然函数计算得出的,而似然函数是针对所分析数据集特异性的。因此,试图比较拟合于不同数据集的模型的AIC值是毫无意义的。 另请注意,我们用来评估一个模型拟合优于或劣于另一个模型的是AIC的差值,而非AIC值的比值。该比值无法直接解读,因此不予报告。
因此,在 Prism 中解读 Cox 回归的 AIC 值的最佳方式,是将指定模型的 AIC 值与拟合同一数据的零模型或另一个(竞争)指定模型进行比较。 与零模型比较时,指定模型的AIC值越小,表明所选参数改善了模型的拟合效果。在比较两个竞争模型时,在考虑各模型包含的参数数量的情况下,AIC值较低的模型被认为具有更好的整体拟合效果。
关于AIC的深入信息
在比较模型时(例如,比较基于同一数据的两个竞争模型,或比较指定模型与零模型),可以利用各模型的对应 AIC 值来计算每个模型正确的“概率”(在假设这些是唯一可能的模型,因此其中一个必定正确的前提下)。为此,我们可以利用两个 AIC 值之间的差值。 首先,为每个模型定义一个新值:
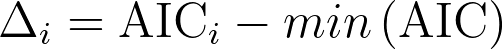
其中 AICi 是该模型的 AIC 值,min(AIC) 是被比较模型中所有可能 AIC 值中的最小值。请注意,对于 AIC 值最小的模型,AICi 将等于 min(AIC),因此该模型的 Δi 为零。一旦获得了每个模型的 Δ 值,即可使用以下公式计算每个模型正确的“概率”:
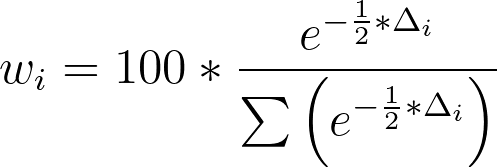
举例来说,考虑比较两个具有以下 AIC 值的模型:
•模型 1 AIC:283
•模型 2 AIC:285
因此,这两个模型的Δ值如下:
•模型 1 Δ:0
•模型 2 Δ:2
各模型正确的概率计算如下:
•模型 1 的概率 w:73.11%
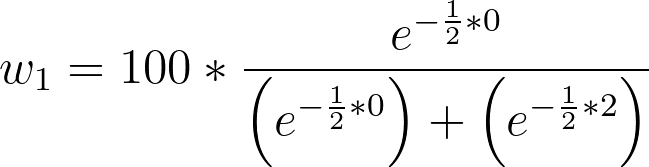
•模型 2 正确率:26.89%
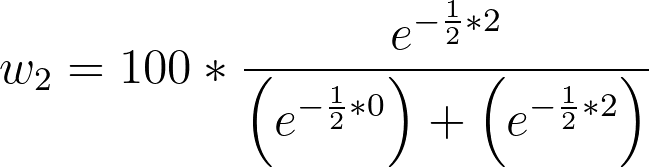
该方法可扩展以处理任意数量模型的比较,但需注意,此方法的假设是待比较的模型中存在一个“真实”模型(尽管在实际应用中,这一假设可能完全不成立)。
偏对数似然 (LL)
似然度的概念在数学上相当复杂,它被用于Cox比例风险回归分析中估计最佳拟合参数值的过程。然而,利用偏对数似然度评估模型拟合优度的方法(幸运的是)相当简单。 一般而言,在比较两个拟合同一数据的模型时,对数似然值更大的模型被视为“拟合”更好。请注意,这些对数似然值通常为负数!在此情况下,数值越大即表示负值越小。因此,负值越小的模型被视为“拟合”更好的模型。
选中此选项后,结果中将给出无协变量模型(零模型)和指定模型的偏对数似然值。如果所选模型的偏对数似然值小于零模型的负对数似然值,则表明输入数据由指定模型生成的可能性大于由零模型生成的可能性。 然而,通常使用各模型的 AIC 值来确定哪个模型“更好”(AIC 值越小,表示模型拟合度“更好”)。
负两倍偏对数似然值 (-2*LL)
与Prism在本结果部分报告的其他数值一样,该值与偏对数似然相关,可用于评估模型对给定数据的拟合程度。 如前所述,在计算AIC时会直接使用“-2*(部分对数似然)”这一数值。幸运的是,一旦获得了部分对数似然(由Prism报告),计算该值只需将其乘以-2即可!其他程序和书籍有时会以其他等效形式呈现该公式:
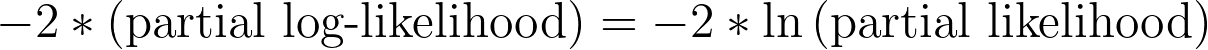
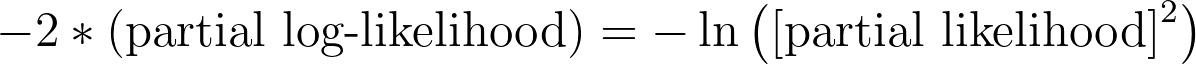
伪R²
在评估回归分析的“拟合优度”时,通常会涉及R平方的概念。该指标可估算模型解释的方差,在进行多元线性回归时非常有用,但无法为Cox比例风险回归计算相同的指标。因此,人们提出了多种“伪R平方”的替代指标。 请注意,这些值与R²的数学含义并不相同。伪R平方值并不代表指定模型解释的方差比例。相反,这些伪R平方值通常用于比较同一数据集上多个模型的拟合优度。
如果在Cox比例风险回归的参数对话框中选中该选项,Prism将报告Cox-Snell R平方(有时也被称为“广义”R平方)。该值是根据以下公式,利用指定模型和零模型(不含协变量的模型)的似然值计算得出的:
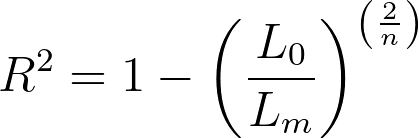
其中 Lm 是指定模型的偏似然值(注意,不是对数似然值),L0 是无协变量的模型(零模型)的偏似然值,n 是模型中使用的观测值数量(包括删剪观测值)。
从该伪R²的计算公式中可以看出,当模型对数据的拟合效果更好(即 Lm 的偏似然值更高)时,该分数会变小,而 R² 值则变大。当给定模型的偏似然值较低时,该分数变大,相应的 R² 值则变小。 与普通(最小二乘)回归中的R²值类似,该公式的最小值为0(若指定模型的偏似然与零模型相同,则R²将等于零)。然而,与标准R²不同,该伪R²的上限并非1!相反,若模型完美拟合数据且模型似然为1,则所得公式为:
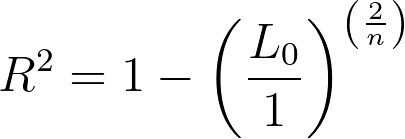
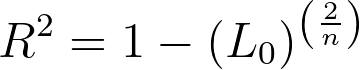
零模型的偏似然值通常极小,但并非零。因此,Cox-Snell R² 的最大值依赖于零模型的似然值,可能非常接近 1(有时甚至接近到计算机无法计算出差异),但未必等于 1。
总结如下:
•该伪R²的最小值为0.0
•该伪R²的最大值小于1.0,但在许多情况下非常非常接近1.0