样本的标准差与总体标准差并不相同
根据一组样本值计算标准偏差非常简单。但这个标准偏差有多准确呢?仅仅是偶然,您可能恰好获得了数据分布非常集中的样本,导致标准偏差较低;或者您可能恰好获得了数据分布比总体更为分散的样本,导致标准偏差较高。您的样本标准偏差可能不等于,甚至远低于总体标准偏差。
标准差的95%置信区间
您可以用95%置信区间(CI)来表示任何计算值的精确度。虽然不常这样做,但计算标准差的置信区间确实是可行的。我们将在下一节中进一步讨论置信区间,该节将解释均值的置信区间。而这里我们讨论的是标准差的置信区间,两者有很大不同。
标准差置信区间的解读非常直观。您必须假设数据是从高斯分布中随机且独立抽取的。您根据该单个样本计算出标准偏差及其置信区间,并利用它对整个总体的标准偏差进行推断。您可以有95%的把握认为,该标准偏差的置信区间包含总体的真实标准偏差。
标准差的置信区间有多宽?当然,答案取决于样本量(N),如下表所示。
N |
标准差的95%置信区间 |
2 |
0.45×标准差 至 31.9×标准差 |
3 |
0.52×标准差至6.29×标准差 |
5 |
0.60*SD 至 2.87*SD |
10 |
0.69*SD 至 1.83*SD |
25 |
0.78*SD 至 1.39*SD |
50 |
0.84*SD 至 1.25*SD |
100 |
0.88*SD 至 1.16*SD |
500 |
0.94*SD 至 1.07*SD |
1000 |
0.96*SD 至 1.05*SD |
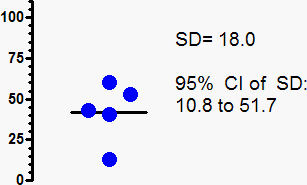
根据上图所示的五个数值计算出的标准偏差为18.0。但这些数值所抽样的总体真实标准偏差可能截然不同。 由于样本量 N=5,95% 置信区间从 10.8(0.60×18.0)延伸至 51.7(2.87×18.0)。当仅根据五个数值计算标准差时,该标准差的 95% 置信上限几乎是下限的五倍。
大多数人都会惊讶于小样本对标准偏差的估计竟如此不准确。在小数据集上,随机抽样会产生巨大影响,导致计算出的标准偏差与真正的总体标准偏差相差甚远。
请注意,置信区间并非对称的。为什么?由于标准差总是正数,下限不能小于零。这意味着上置信限通常比下限延伸得更远。在小样本中,这种不对称性非常明显。
若您想自行计算这些置信区间,请使用以下 Excel 公式(N 为样本量;α 取值为 0.05 对应 95% 置信水平,0.01 对应 99% 置信水平,依此类推):
下限:=SD*SQRT((N-1)/CHIINV((alpha/2), N-1))
上界:=SD*SQRT((N-1)/CHIINV((alpha/2), N-1))