Cox比例风险回归假设基线风险率 (h0(t))、预测变量 (xi) 的值以及参数系数 (βi) 之间存在如下关系:
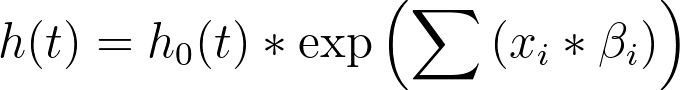
在进行Cox比例风险回归时,分析过程的第一步是估计模型中β系数的控制数据。这通过一种称为最大似然估计(MLE)的方法来实现。 该技术涉及的数学内容已超出本指南的范围,但需要注意的是,根据所分析的数据类型以及数据中是否存在并列情况,通常有三种不同的方法用于最大似然估计。有关这些β系数解读的详细信息,请参阅本页的更多内容。
在收集生存数据时,表示经过时间的变量被视为连续变量,但通常以离散方式进行测量。 研究中每个个体的状态会按小时、每天、每周、每月等频率进行检查,而用于分析的记录时间通常在此层级截断。例如,在为期4个月的研究中,我们可能仅记录某个体在第6周发生了目标事件,而非精确记录该个体在发生目标事件前经过的具体天数(或小时、分钟、秒等)。 然而,需要注意的是,即使采用这种数据记录方法,经过时间仍被视为连续变量。因此,研究中常会出现多名受试者的记录生存时间相同的情况。这在经过时间分析中被称为“并列”。
当数据中不存在平局(或仅有少量平局)时,可采用“精确”法通过最大似然估计(MLE)来确定模型中的β系数(这也是Prism软件的默认设置)。然而,当事件发生时间出现大量平局时,该方法的计算量将变得极其庞大,因此会采用近似法来计算所需的β系数值。常用的近似法主要有两种:
1.布雷斯洛近似法
2.埃弗隆近似法
布雷斯洛近似法是这两种方法中较早出现的一种,当数据中存在并列值时,许多统计软件包将其作为默认方法。然而,埃夫隆近似法通常被认为能提供更准确的结果。 当数据中出现少量并列值时,这三种方法得出的结果应非常接近。当并列值数量较多时,Prism将自动采用埃夫龙近似法来确定β系数的值。不过,您可以通过分析对话框中的“模型”选项卡中的控件指定首选的方法。
本指南后续章节将介绍如何在 Prism 中执行 Cox比例风险回归,并指导您如何解读 Prism 通过此分析生成的结果。