虽然赤池方法的理论基础难以理解,但计算过程简单,且结果易于解读。
任何模型对数据集的拟合程度,都可以用赤池提出的“信息准则”(AIC)来概括。 如果您接受非线性回归的通常假设(即曲线周围点的散布服从高斯分布),则 AIC 由两个模型的平方和与自由度之和通过一个简单的方程定义。AIC 值本身无法直接理解,因为其单位依赖于您对数据使用的单位。
在比较模型时,仅需关注两个AIC值之间的差值。计算差值时,单位会相互抵消,最终结果为无量纲。
对于最小二乘回归,计算公式为:

对于Poisson回归,其方程为:

逻辑回归的AICc方程与Poisson回归的方程几乎完全相同(在方程中用参数个数代替自由度)。
该公式现在具有直观的意义。与F检验类似,它平衡了由平方和(或Poisson回归中的似然比)评估的拟合优度变化与自由度变化(源于待拟合参数数量的差异)。由于模型1是简单模型,其拟合效果几乎总是较差,因此SS1将大于SS2。 由于分数的对数总是负数,因此第一项为负。模型1的参数较少,因此自由度更多,使得最后一项为正。如果净结果为负,这意味着平方和的差异大于根据参数数量差异所预期的值,因此可以得出结论:复杂模型更可能成立。
Prism 报告的两个 AICc 值之间的差值,即为简单模型的 AICc 减去复杂模型的 AICc。当更复杂(参数更多)的模型具有更低的 AICc 且因此被选中时,Prism 报告的 AICc 差值为正数。当简单模型具有更低的 AICc 且因此被选中时,Prism 报告的 AICc 差值为负数。
上述公式有助于您理解 AIC 的运作原理 - 即在拟合优度变化与参数数量差异之间取得平衡。但您无需使用该公式。只需查看各个 AIC 值,并选择 AIC 值最小的模型。该模型最有可能正确。
实际上,Prism 报告的并非 AIC,而是 AICc。该值包含针对小样本量的修正。其计算公式稍显复杂,但在小样本量下更为精确。随着样本量增大,AIC 和 AICc 几乎相同。
请注意,这些计算基于信息论,并未采用传统的“假设检验”统计范式。因此,这里不存在P值,不会得出关于“统计学显著性”的结论,也不会“拒绝”某个模型。
基于AICc值的差异,Prism会计算并报告每个模型正确的概率,这些概率之和为100%。 如果一个模型比另一个模型正确的可能性高得多(例如 1% 对比 99%),您应选择该模型。如果可能性的差异不大(例如 40% 对比 60%),则表明两个模型都有可能正确,因此需要收集更多数据。这些概率通过以下公式计算,其中 Δ 表示 AICc 值之间的差值。
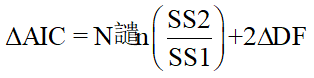
请注意,此方法仅比较您所选的两个模型的拟合情况。可能存在一个您未选中的第三个模型,其拟合效果远优于您所选的任何一个模型。