在生存分析中,因变量是指从某个定义的“起始时间”到另一个定义的“终点”之间所经过的时间。这一经过时间通常被称为生存时间,因为此类研究中常见的“终点”是受试者的死亡。 几乎所有类型的生存分析,其主要目标都是估计或理解该响应变量与一个或多个预测变量之间的关系。这些预测变量可能是由实验条件所确定的(例如接受某种治疗与接受另一种治疗或对照组),也可能是观察变量(例如研究参与者的性别)。
例如,生存分析可用于评估一种新型癌症治疗方法的效果,具体方法是测量接受该新疗法的个体与接受标准治疗的对照组个体之间的生存时间。通过比较各组个体的生存时间,可以获得关于新疗法疗效的信息。
再举一个生存分析的例子:假设您供职于一家公司,该公司生产一种被全国各地实验室广泛使用的实验室设备。 您被指派研究该设备中某个特异性组件的失效问题。除了测量每个设备在组件失效前的使用时间外,您还可以记录每个实验室内的环境温度和相对湿度(假设这些参数随时间保持不变)。在本示例中,生存分析将使您能够考察温度(或湿度)与设备内组件失效时间之间的潜在关系。
一旦确定了预测变量与生存时间之间的关系,这些信息还可用于估算其他受试者或个体随时间推移的生存概率(假设已知这些个体的预测变量值)。
这听起来很像多元线性回归
如果您熟悉多元线性回归模型,可能会觉得生存分析试图实现相同的目标(即揭示某个被测响应变量与一组预测变量之间的关系)。 正如本指南后文将展示的那样,多元线性回归与某些生存分析技术确实存在相似之处(参见:Cox比例风险回归)。然而,生存数据具有一些重要特征,导致典型的多元线性回归方法并不适用于此类数据的分析。
生存数据通常具有高度偏斜度
如前所述,生存分析的响应变量是每个观测对象(受试者、个体等)达到某个定义终点之前所经过的时间。这对响应变量值的分布具有重要影响。首先,由于我们测量的是经过时间,因此所有值均为正数(生存分析中不存在“负时间”)。 其次,在观察或抽样生存时间时,所得数值通常具有高度的偏斜度。请看下图所示的一组5000个观测值的生存时间直方图
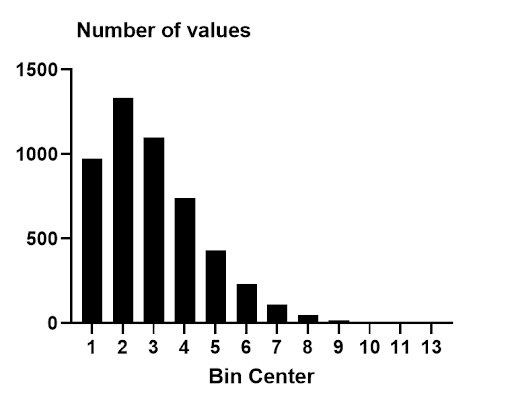
大部分生存时间集中在1到3之间(近70%的观察值落在这一区间内)。然而,也有多组观测值延伸至13。直方图右侧的这些值被认为使分布具有“长右尾”,或者说该分布是“右偏斜的”。 这些数据虽为模拟数据,但展现了真实生存数据中常见的右偏分布特征。正因这种偏斜度,许多基于正态(高斯分布)的假设和技术无法应用。
删剪数据
生存分析与标准线性回归技术之间的另一主要区别在于删剪数据的普遍存在。这是生存分析中如此重要的一个主题,以至于在指南中专门为其设置了独立的页面。