Cox比例风险回归的目标是利用观测到的事件发生时间数据,在预测变量的数值与风险率(风险函数)之间建立数学关系。基于这些信息,可以确定生存函数,从而得到每个个体随时间变化的估计生存率。然而,为了简化数学表达,实际建模的对象是风险率。 以下是Cox比例风险回归试图定义的一般模型:
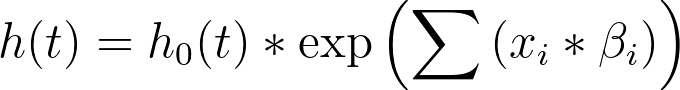
其中:
•h(t) 是风险率(作为时间的函数)
•h0(t) 是基线危险率(定义如下)
•xi 是每个预测变量 i 的取值 - 请注意,在 Cox 回归中,每个观测值到目标事件的经过时间并不被视为预测变量。相反,预测变量代表任何可能影响该经过时间(即生存时间)的其他测量变量
•βi 是每个预测变量 i 的系数
Cox比例风险回归最重要的方面之一是基线风险的假设,在上式中表示为 h0(t)。这本身是一个随时间变化的函数,代表某条曲线(如上一节所示),该曲线描述了感兴趣事件的发生频率与时间之间的关系。 重要的是,基线风险的特异性形状并不重要(它可能起初较高并随时间下降;可能起初较低并随时间上升;或者可能包含许多峰谷)。事实上,进行Cox比例风险分析完全不需要了解基线风险率的形状或性质。正是这一基线风险可以采用任何分布的假设,使得Cox比例风险分析成为一种半参数分析。
关于基线风险率需要了解的关键点是:它代表了当所有预测变量的值被设为零(或对于分类型变量,设为其参考水平)时的风险率。这可以通过上述方程,将 xi 设为零来展示:
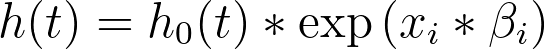
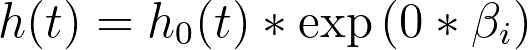
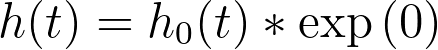
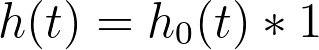
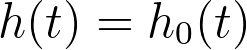
因此,基线风险率就是当所有预测变量的值设为零时的风险函数!而总体中任何个体的风险率,可以通过将该基线风险率乘以其特定预测变量值决定的某个量来确定(即上文风险率方程中由“exp(Σ(xi*βi))”表示的部分)。换言之,任何个体的风险率都与一个共同的基线风险率成正比。
基于基线风险函数这一假设,另一个非常有趣的结果是:当我们考察两个预测变量取值不同的个体时的风险会发生什么。为了简化问题,我们考虑一个仅含单个预测变量(xi)的模型,其中一个个体的该变量值为“a”,另一个个体的该变量值为“b”。这两个个体的风险函数分别为:
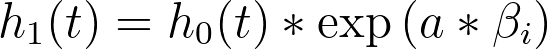
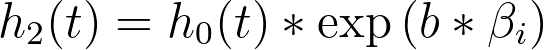
而这两个风险函数的风险比为:
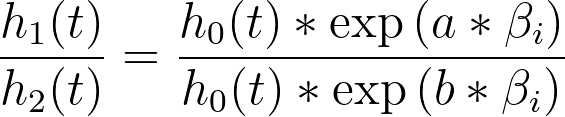
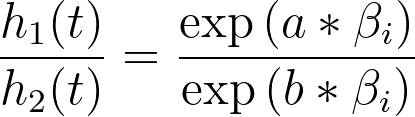
分子和分母中的基线风险相互抵消,剩下一个随时间保持恒定的分数(我们假设预测变量的值随时间不变)。换言之,总体中任意两个个体的风险比在任何时刻都是恒定的。换一种说法,总体中两个个体的风险总是成比例的。 正是这种比例关系的概念,赋予了该分析其名称:Cox比例风险回归。下图给出了这些比例关系的图形示例:黑色曲线是理论上的基线风险率,而蓝色和红色曲线分别代表单一预测变量两个不同值对应的风险率(蓝色曲线为某个任意值“α”,红色曲线为该值的两倍“2α”):
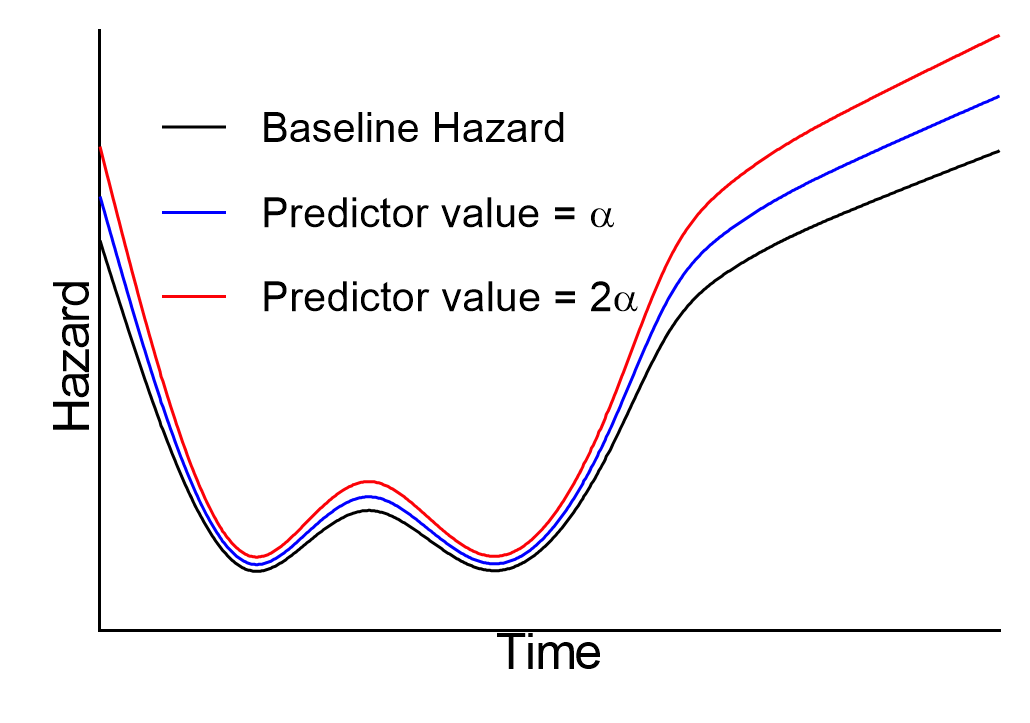
可以看出,这些曲线之间的垂直距离在各个时间点并非恒定,但任意两条曲线在任意时间点的风险比将保持不变。因此,随着基线风险值的增加,曲线之间的距离会增大,而每条曲线仍保持相似的形状,且 - 重要的是 - 这些曲线永远不会相交。
后续章节将深入探讨这些危险率与生存函数之间的数学关系,利用该关系,在给定模型中预测变量的数值集的情况下,可以绘制出研究期间任何个体在所有时间点的估计生存曲线。