如果将“权重”选项卡中的选项保留为默认设置(即不进行权重调整),而散点图实际上与Y值相关,会发生什么情况?当然,答案是“视情况而定”。这取决于散点图的范围有多大,以及Y值的分布范围有多广。本文剩余部分将通过本示例,并模拟多个数据集,来探讨当拟合操作不当的情况下会发生什么。
模拟
我选择了一个非常简单的模型 - 一条直线。我模拟的数据使得沿直线任意一点的离散度标准差与该点的 Y 值成正比。下图展示了一组模拟数据集。您可以清楚地看到,随着直线向上延伸,重复测量结果之间的离散度逐渐增大。
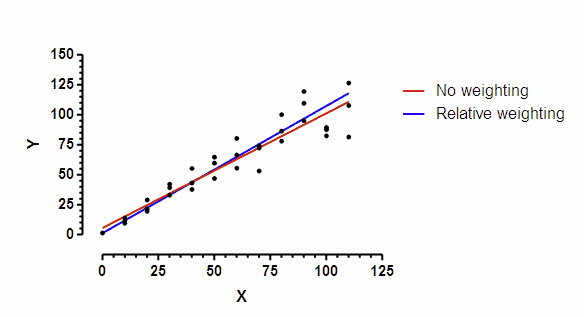
该直线是通过“非线性”回归拟合得到的。Prism 的线性回归分析不提供差异加权功能,但“非线性”回归在拟合直线时提供了线性回归分析中不具备的多种选项。
红色曲线采用默认设置 - 无加权;最小化平方和。蓝色曲线采用相对权重。当预期重复测定残差的标准差与Y值成正比时,此选项最为合适。这两条曲线并不完全一致。
我使用 Prism 的蒙特卡洛分析模拟了 5000 个此类数据集。对每个模拟数据集,均分别进行了无权重回归和加权(相对权重)回归拟合。对于这 5000 个数据集中的每组分析,我都记录了斜率的控制数据及其标准误差 (SE)。
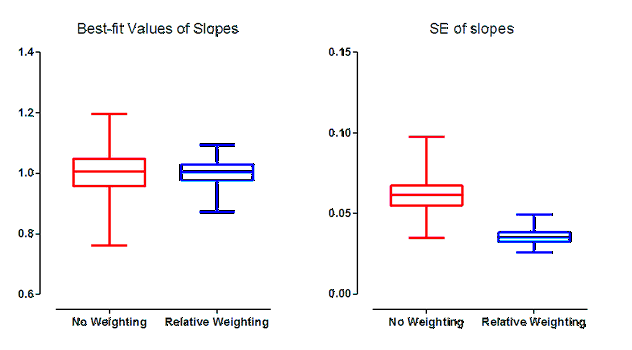
由于重复实验间的离散程度与Y成正比,因此相对权重是合适的。这些模拟结果以蓝色显示。红色结果则显示了采用等权重(默认设置)进行回归分析时的结果。箱形图的范围从第25百分位数延伸至第75百分位数,中间线为中位数(第50百分位数)。箱线向下延伸至最小值,向上延伸至最大值。
上图左侧展示了最佳拟合斜率的分布情况。选择错误的加权方案并不会系统性地导致最佳拟合斜率过高(过陡)或过低(过缓)。事实上,无加权拟合与相对权重拟合所得的控制数据中位数几乎完全一致。 但请注意,未加权的结果在斜率分布上要宽得多。由于这些是模拟数据,我们知道真实斜率(1.0),并能量化每个数据集的最佳拟合斜率与该理想值的偏差。 未采用差异加权进行拟合时(红色),误差中位数为0.04610;而采用相对权重进行模拟时(蓝色),误差中位数为0.02689。在本示例中,选择错误的加权方案导致误差中位数增加了71%。
上图右侧展示了斜率标准误差的分布情况。 当对所有数据点采用等权重拟合时,斜率的标准误差平均值明显更高,且一致性更差(离散度更大)。无权重拟合的标准误差中位数比加权拟合的标准误差中位数高出73%。由于置信区间的宽度与标准误差成正比,这意味着在无权重拟合的情况下,置信区间的宽度增加了73%。
由于这些是模拟数据,我们知道真实总体斜率(即1.0)。 因此,我们可以针对每次模拟验证所报告的95%置信区间是否包含真实值。在采用相对权重法模拟的情况下,95.3%的数据集其95%置信区间包含了真实值。而当对同一组数据集采用无权重分析时,仅有92.6%的“95%”置信区间包含了真实值。
总结
综上所述,当我们在本示例中选择了错误的加权方案时:
•斜率的控制数据精度较低。
•斜率的标准误差更大,因此置信区间更宽。
•尽管95%置信区间变宽了,但仍不够宽。在模拟中,"95%"置信区间包含真实值的概率不到95%。
本示例仅仅是一个例子。在其他例子中,权重方法的选择可能影响较小。但在另一些例子中,其影响可能更大。因此,尝试选择合适的权重方案是值得的。