在拟合对数剂量(log(dose))与反应关系曲线之前,通常会先对数据进行标准化处理。本页将解释为何在此情况下不应使用加权回归。
对未归一化数据进行加权拟合 - 效果极佳
下图展示了一组模拟数据,反映了常见的情况。当Y值较大时,重复测量结果之间的离散程度也更大。实际上,这些数据是经过模拟生成的,因此重复测量结果之间的标准差与Y值成正比。
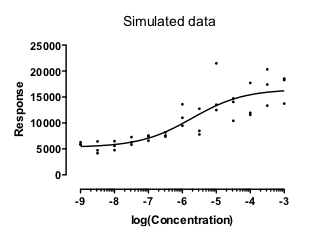
使用相对加权对这些数据进行拟合效果极佳。这将点与曲线之间相对距离的平方和最小化。换言之,它使以下表达式最小化:
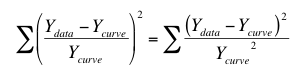
我进行了 10,000 次模拟,发现每次拟合效果都很好,并给出了合理的结果(EC50 值在数据范围内)。到目前为止,这并不令人意外。数据拟合是基于一个与模拟数据所用方法完全匹配的模型进行的,而这些拟合效果很好。
对归一化数据进行加权拟合 - ugh
人们常喜欢将剂量-反应数据归一化,使Y值范围在0%至100%之间。若对这些归一化数据进行加权非线性回归拟合,会发生什么?
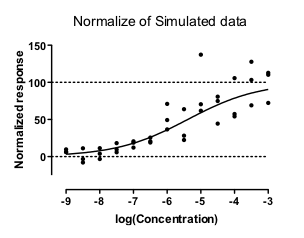
我通过模拟实验回答了这个问题。在1,000组模拟数据集中,有223组完全无法拟合。此外,60组模拟数据给出了荒谬的结果,其EC50值超出了数据范围。剩余72%的模拟结果看似正常,但其中部分的置信区间非常宽。
这是怎么回事?
对于未经归一化的数据,最佳拟合曲线在X = -4处的Y值是X = -8处Y值的3.05倍。 由于权重与曲线的 Y 值平方成正比,因此曲线顶部附近(X = -4)的点所获得的权重是曲线底部附近(X = -8)的点的 3.052 倍,即 9.28 倍。
对于归一化数据,情况则大不相同。在第一个模拟数据集中,最佳拟合曲线在 X = -4 处的 Y 值是该曲线在 X = -8 处 Y 值的 17.77 倍。 由于权重与曲线的 Y 值平方成正比,因此曲线顶部附近的点(在 X=-4 处)所获得的权重是曲线底部附近点(在 X=-8 处)的 17.772 倍,即 315.8 倍。 由于曲线顶部的点获得的权重远高于底部的点,底部的点实际上被忽略了,导致整个曲线拟合效果不佳。
另一个问题是,标准化数据集底部附近的部分 Y 值为负数。当部分值为负而部分为正时,权重系数实际上完全没有意义。
总结:归一化后,重复样本间的标准差不再与Y值成正比,因此相对权重法并不适用。
核心要点
加权非线性回归的核心思想在于,使回归所采用的加权方案与实际数据的变异性相匹配。如果对数据进行标准化处理,任何常规的加权方案都将难以奏效。
如果您确实希望将数据展示在0%至100%的标准化坐标轴上,可以这样做。首先使用适当的加权方案将模型拟合到实际数据上。然后对数据和曲线同时进行标准化处理。