尽管非线性回归顾名思义是用于拟合非线性模型的,但某些推断实际上假设模型的某些方面接近线性,从而使得每个参数值的不确定性呈对称分布。
对方程进行重新参数化可以使不确定性更加对称,从而使标准误差更易于解释,并使对称的渐近置信区间更具参考价值。Prism 可以计算非对称置信区间,当您选择这种方法时,方程的参数化方式就不再那么重要了。
什么是重新参数化?
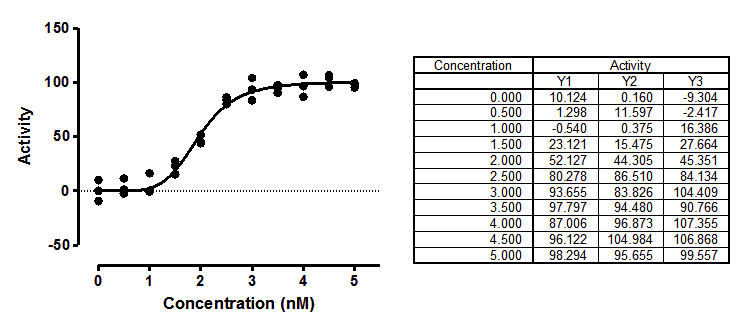
将 sigmoidal 酶动力学数据拟合到标准模型时,通常使用以下两种形式的模型:
Y=Vmax*X^h/(Khalf^h + X^h)
Y=Vmax*X^h/(Kprime + X^h)
这两个方程是等价的。它们都拟合 Vmax(外推至极高底物浓度时的最大活性)和 h(Hill斜率,描述曲线的陡峭程度)。但一个模型拟合 Khalf(达到最大速率一半所需的浓度),另一个则拟合 Kprime(对底物作用的一种更抽象的度量)。
哪种模型更好?两者是等价的,且 Kprime 等于 Khalfh,因此它们将生成完全相同的曲线。
由于平方和与自由度数均完全相同,因此无论选择该模型的哪种形式,将其与其他模型进行比较都会得到完全一致的结果。
参数分布并非总是对称的
通过模拟可以确定参数不确定性的对称程度。我模拟了 sigmoidal 酶动力学,采用 Vmax=100、h=5、Kprime=25(因此 Khalf=5),并使用标准差为 7.5 的高斯散布。X 值与上图中的数据一致,每个 X 值对应三组 Y 值。Prism 可以轻松重复此类模拟。 我重复了 5000 次模拟,将每条曲线分别拟合到两种模型形式中,列出了 Kprime 和 Khalf 的最佳拟合值,并计算了各自的偏度。
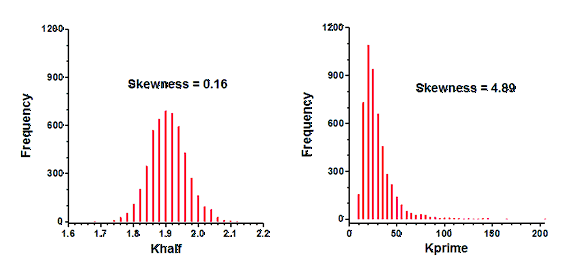
显然,Khalf的分布非常对称,且呈高斯分布。其偏度接近于零,这与对称分布的预期一致。相比之下,Kprime的分布则相当偏斜。请注意,部分模拟中Kprime的最佳拟合值大于100。偏度值(4.89)证实了肉眼观察到的明显现象 - 该分布远非对称。
使用 Hougaard 偏度量化不对称性
上述结果是通过大量模拟运行获得的。其实还有一种更简便的方法来判断参数的对称性。Prism 可以计算每个参数的 Hougaard 偏度,其计算基于方程、数据点数量、X 值的间隔以及参数的数值。对于该模拟数据集,Khalf 的 Hougaard 偏度为 0.09,而 Kprime 的 Hougaard 偏度为 1.83。 经验法则是:当霍加德偏度绝对值大于 0.25 时,通常会因不对称性而出现问题;当该值大于 1.0 时,则会出现严重问题。这些数值无需模拟即可通过单个数据集计算得出,表明在拟合 Khalf 时,对称置信区间将比拟合 Kprime 时更为准确。
请注意,虽然 Prism 6 和 7 在无权重拟合中能正确计算 Hougaard 偏度,但在选择不等权重时计算结果有误。此问题已在 Prism 8 中修复。
非对称参数的后果
理想情况下,置信区间应易于解释。95% 置信区间有 95% 的概率包含参数的真实总体值,且有 5% 的概率遗漏该值。
在分析真实数据时,我们永远无法得知真实参数的值,因此也无法确定置信区间是否包含该值。但在模拟数据时,由于已知参数的真实值,因此可以量化置信区间的覆盖率。 我设置了上述相同的模拟实验,将每个数据集分别拟合到两个方程中,并统计了每个置信区间是否包含真实参数值。下表显示了在5,000次模拟中,渐近对称置信区间未包含真实参数值的比例(Kprime为25次,Khalf为1.9037次)。
“95% CI” |
"99% CI" |
|
理想情况 |
5.0% |
1.0% |
Kprime |
8.8% |
4.8% |
Khalf |
5.1% |
1.0% |
这些结果表明,Khalf 表现良好,这与其对称性相符(见上文)。预计 95% 置信区间在 5.0% 的模拟中会漏算真实值。实际上,这种情况发生了 5.1% 的次数。同样,预计 99% 置信区间在 1.0% 的模拟中会漏算真实值,而实际情况也正是如此。 相比之下,Kprime 的表现较差。计算出的 95% 置信区间不够宽,因此在 8.8% 的模拟中未能包含真实值。99% 置信区间同样不够宽,导致在 4.8% 的模拟中未能包含真实值。因此,本应是 99% 置信区间的计算结果,实际上变成了 95% 置信区间。
这些模拟结果表明,选择拟合 Khalf 的方程比选择拟合 Kprime 的方程更具优势。Khalf 具有对称分布,因此基于这些拟合计算出的置信区间可以按字面意思进行解释。相比之下,Kprime 具有非对称分布,其置信区间无法按字面意思进行解释。
若要求Prism呈现非对称轮廓似然置信区间,参数化形式则无关紧要
若选择非对称轮廓似然置信区间,则方程形式的选择便无关紧要。两种情况下的覆盖率将完全相同,且均非常接近95%或99%。在此情况下,您可以选择符合教科书和论文的方程形式,或选择符合您思维方式的方程形式。若您倾向于图形化思考,请选择Khalf;若您倾向于机制化思考,请选择Kprime。