1. 创建数据表
在“欢迎”或“新建表格”对话框中,选择创建 XY 数据表。
如果您是初次使用,请选择示例数据:线性回归 - 比较斜率。
如果您要输入自己的数据,请选择子列格式。若需输入重复测量数据,请选择“重复值”。Prism 可自动绘制误差线。您也可以选择输入已计算出均值和标准差(或标准误)的数据。在此情况下,若需考虑各数据点间标准差的变异性,请使用非线性回归拟合直线。
2. 输入数据
若选择样本数据,您将看到以下选项:
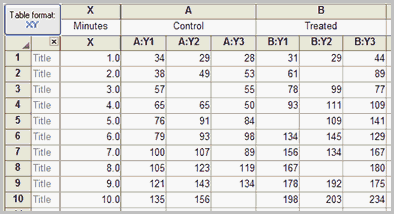
如果您为多个数据集(A、B 和 C 列)输入 Y 值,Prism 将分别报告 X 与 YA、X 与 YB 以及 X 与 YC 的回归结果。它还可以检验斜率(和截距)是否存在显著差异。
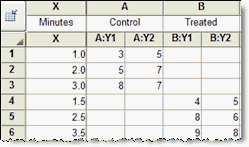
如果不同数据集的 X 值不相同,请像这样为不同数据集使用不同的行:
3. 分析选项
单击“分析”,然后从 XY 分析列表中选择“线性回归”。
强制直线通过指定点(如原点)?
若选择回归分析,可强制使直线通过特定点(如原点)。此时,Prism 仅确定最佳拟合斜率,因为截距已被固定。当科学理论要求直线必须通过特定点(通常为原点,X=0, Y=0),且您仅需了解斜率时,请使用此选项。这种情况很少发生。
请根据实际情况做出判断。例如,考虑蛋白质测定。您测量了多种已知浓度蛋白质的吸光度(Y),以绘制标准曲线。 随后,您希望根据该标准曲线插值未知蛋白浓度。在进行测定时,您已将分光光度计调整为在零蛋白浓度下读数为零。因此,您可能会倾向于强制回归直线通过原点。但这种约束可能会导致直线与数据拟合不佳。由于您真正关注的是直线在未知浓度附近与标准曲线的拟合效果,因此不施加约束通常能获得更好的拟合效果。
如有疑问,应让Prism在无任何约束条件下寻找最佳拟合直线。
线性回归应拟合单个重复样本还是平均值?
若您在每个 X 值处都收集了重复测定的 Y 值,则有两种方法计算线性回归。您可以将每个重复测定视为独立数据点,或者对重复测定的 Y 值求平均值,以确定每个 X 值处的平均 Y 值,并使用这些平均值进行线性回归计算。
当每个数据点的实验误差来源相同时,应将每个重复数据视为独立数据点。如果某个值恰好偏高,没有理由认为其他重复数据也会偏高。这些误差是相互独立的。
当重复测量不独立时,应取重复值的平均值,并将该平均值视为单一数据点。例如,如果重复测量代表同一动物的三次测量结果,且每个 X 值(剂量)对应不同的动物,则这些重复测量不独立。如果某只动物的反应恰好比其他动物更强烈,这将影响所有重复测量结果。此时,重复测量之间不独立。
使用游程检验检验线性偏差
参见游程检验
检验斜率和截距是否存在显著差异
如果您输入了两个或多个数据集的数据,Prism 可以检验斜率是否存在显著差异。