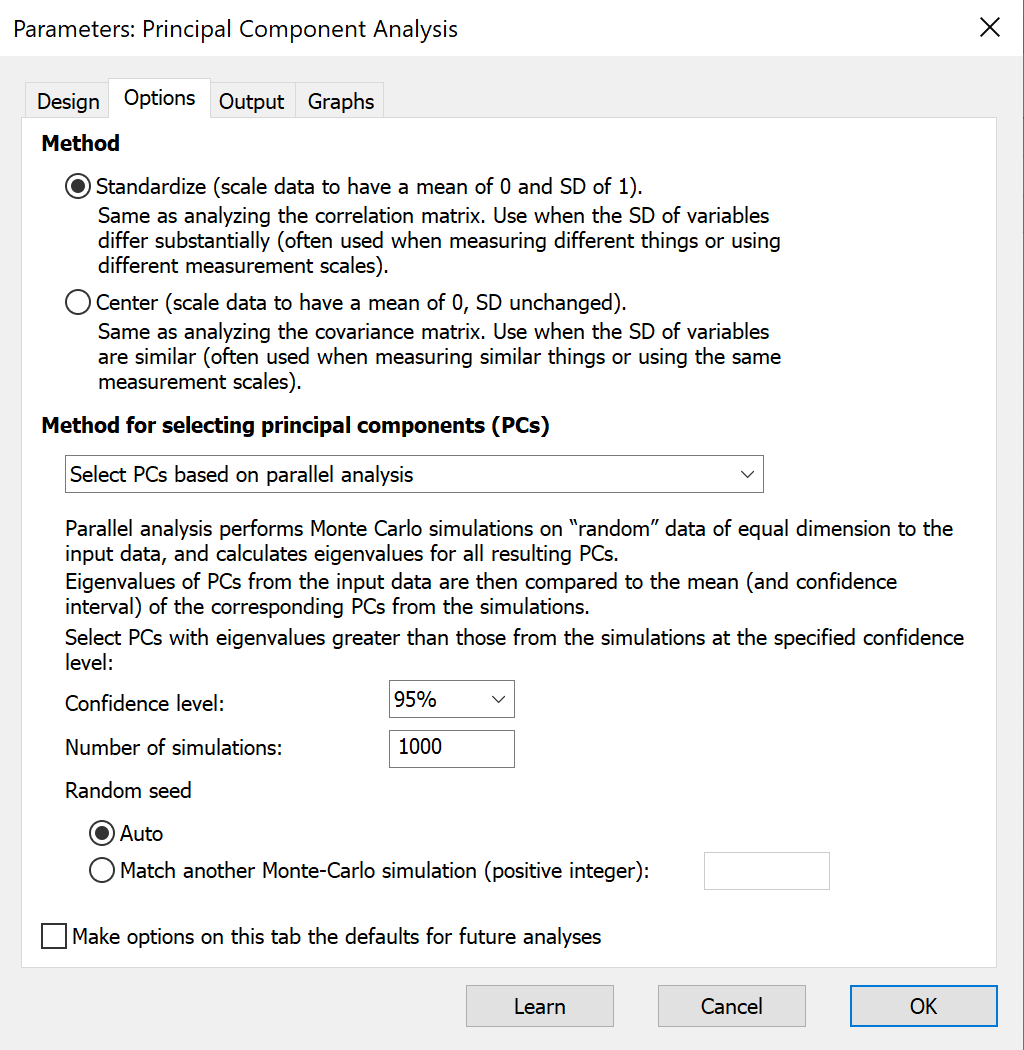
在对话框的“选项”选项卡中,您需要做出两项关键决策,这些决策将对PCA的结果和结论产生重大影响。除非您清楚为何需要采取其他做法,否则我们建议对标准化数据进行PCA分析,并使用平行分析法来确定成分数。
方法
最重要的决定是:对标准化数据还是对中心化数据进行PCA分析。
对标准化数据进行PCA
除非有特异性原因,否则建议采用此方法。这有时也被称为对相关矩阵进行PCA分析。如果您的变量使用不同的单位进行测量,几乎总是应选择此方法。
工作原理:在执行PCA之前,会对变量进行转换,使每个变量的均值为0,标准偏差为1。这将所有变量置于同一量表上,因此当找到主成分时,每个变量的权重是相等的。数学上,
Xstandardized = (Xraw - X̄)/sx
其中 X̄ 是变量值的均值,sx 是其标准偏差。
基于中心化数据的PCA
如果所有变量单位一致,则建议对中心化数据进行PCA,这也称为基于协方差矩阵的PCA。虽然有时这是合适的选择,但这种情况较为罕见。
工作原理:在执行PCA之前,会对变量进行转换,使得每个变量的均值为0,同时保持其标准偏差不变。由于变量未进行缩放,标准偏差大于其他变量的那些变量将主要驱动第一个主成分的计算。数学上,
Xcentered = (Xraw - X̄)
其中 X̄ 是变量值的均值。
主成分数量的选择方法
主成分的选择是确定PCA后降维数据集将具有多少“维度”的过程。在某些情况下,Prism仅针对所选的主成分提供结果(载荷、特征向量、变量的贡献矩阵、变量与主成分的相关矩阵、主成分得分以及案例的贡献矩阵)。
Prism 提供了四种选择主成分数量的方法:
平行分析(推荐)
平行分析是一种优雅的模拟方法,通过确定主成分与模拟噪声生成的成分无法区分的临界点,来选择应包含的主成分数量。以下是平行分析的工作流程:
1.Prism 会模拟大量数据集(默认值为 1000,但可指定其他数值)。每个模拟数据集包含的变量(列)和观测值(行)数量与输入数据相同。
a.对于每个模拟变量,数据通过从均值为 0 的多维正态分布中采样生成。
b.每个模拟变量的标准偏差等于输入数据表中对应变量的标准偏差
2.对每个模拟数据集执行主成分分析(PCA)
3.对于每个主成分(PC),将计算所有模拟数据集的平均特征值
4.对于每个主成分 (PC),使用所有模拟数据集的特征值计算一个上百分位数(默认值为第 95 百分位数)
5.对于每个主成分,Prism 将输入数据中的特征值与从模拟数据集计算出的上百分位数进行比较
6.如果输入数据的特征值大于模拟数据中的上百分位数,则选择该成分;否则不选择该成分。
请注意,如果您选择并行分析来确定主成分(PC)的数量,碎石图将同时显示模拟特征值和您数据中的特征值。
根据特征值选择主成分
传统上,会选择特征值大于 1 的主成分。这被称为凯泽法则。 将“1”作为阈值的依据在于:对于标准化数据,每个变量的标准偏差(及方差)均等于 1。主成分的特征值代表该主成分对原始数据所解释的方差。因此,如果每个原始变量(或列)引入的变异性为 1,则特征值小于 1 的主成分所解释的变异性将少于单列数据。
Prism还提供了选择不同阈值或仅保留前k个特征值最大的主成分的选项(k可在选项中指定)。
基于贡献总方差的百分比选择主成分
另一种常见的(经典)主成分选择方法是保留那些累积贡献了指定百分比总方差且具有最大特征值的主成分。总方差目标百分比的常见选择是 75% 和 80%。
选择所有主成分
最后一种选项是让 Prism 报告所有主成分。此方法虽鲜少实用,但在教学或特定数据探索中可能有所帮助。