双因素方差分析用于确定两个因素如何影响响应变量。例如,您可以测量男性和女性对三种不同药物的反应。
变异来源
双因素方差分析将数据值间的总变异性分为四个组成部分。Prism 软件会分别列出行因子与列因子交互作用所占的变异百分比、行因素所占的变异百分比以及列因子所占的变异百分比。剩余的变异来自重复组(也称为残差变异)。
这些数值(占总变异量的百分比)被 Sheskin 称为标准 omega 平方(方程 27.51 - 27.53),而 Maxwell 和 Delaney 则称之为 R²(第 295 页)。其他人则将这些数值称为 eta 平方或相关系数。
方差分析表
方差分析表将测量值之间的总体变异性(以平方和表示)分解为四个组成部分:
•行与列之间的交互作用。即各列在不同行上表现不一致的行间差异,相当于各行在不同列上表现不一致的列间变异。
•列间变异性。
•行间变异性。
•残差或误差。指与行和列之间的系统性差异无关的重复组间变异。
方差分析表展示了平方和如何被划分为这四个分量。大多数科学家会跳过这些结果,除非您深入学习过统计学,否则这些结果并无特别的参考价值。 对于每个分量,表格显示了平方和、自由度、平均平方及F比值。每个F比值都是该变异源的均方值与残差平均平方之比(在重复测量方差分析中,某个F比值的分母是配对平均平方而非残差平均平方)。 若零假设成立,F 比值通常接近 1.0;若零假设不成立,F 比值通常大于 1.0。F 比值本身信息量有限,但可用于计算 P 值。
标准效应量
本节所述的功能和特性仅适用于我们的全新 Pro 和 Enterprise 订阅。了解更多... |
Prism 会为方差分析 (ANOVA) 结果报告标准效应量,包括η²、偏η²(ηp²)和科恩的 f 值。由于这些效应量适用于多种 ANOVA 设计(单因素方差分析、双因素方差分析、三因素方差分析及多因素 ANOVA; 常规设计和重复测量设计),关于这些效应量如何计算和解读的详细信息,请参阅专门的“理解方差分析效应量”页面。
P 值
双因素方差分析将因变量的总体方差分解为三个分量,外加一个残差(或误差)项。因此,它计算的 P 值用于检验三个零假设(重复测量方差分析还会增加另一个 P 值)。
交互作用P值
零假设是列(数据集)与行之间不存在交互作用。更准确地说,零假设认为列之间的任何系统性差异在每一行中都是一致的,行之间的任何系统性差异在每一列中也都是相同的。通常,交互作用检验是这三项检验中最重要的一项。如果列代表药物,行代表性别,那么零假设就是药物之间的差异在男性和女性中是一致的。
P值回答了以下问题:
若零假设成立,随机抽样受试者后,其交互作用程度达到(或超过)当前观察值的可能性有多大?
下图左侧显示无交互作用。该治疗对男性和女性的效果大致相同。 相比之下,右侧图表显示了显著的交互作用。治疗效果在男性(治疗使浓度升高)和女性(治疗使浓度降低)中完全不同。在本示例中,治疗效果对男性和女性的方向相反。但交互作用检验并非检验效果是否方向相反,而是检验平均治疗效果在每一行(本示例中即每种性别)中是否相同。
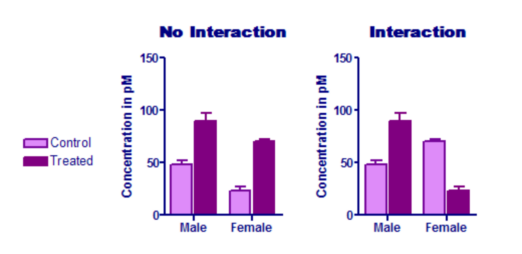
进行交互作用检验时,您需要输入重复值或均值与标准差(或标准误)以及样本量(N)。如果您为每个行/列组合仅输入了一个值,Prism 会默认不存在交互作用,并继续进行其他计算。根据您的实验设计,这种假设可能合理,也可能不合理。
列因子 P 值
零假设是,在总体中,各列的均值(完全忽略行)是相同的,且我们观察到的列均值之间的所有差异均由随机因素造成。在示例图表中,对照组和处理组的结果被输入到不同的列中(男性和女性被输入到不同的行中)。零假设是,该处理无效,因此对照组和处理组的数值差异仅由随机因素造成。 P 值回答了这个问题:如果零假设成立,随机获得的列均值差异(或更大差异)与实际观察到的差异相等的概率是多少?
在上图左侧图表所示的例子中,列因子(处理)的 P 值为 0.0002。这表明处理具有统计学显著效应。
在上图右侧图表所示的例子中,列因子(处理)的 P 值非常高(0.54)。 平均而言,该处理效应与随机变异无法区分。但在本示例中,该P值并无实际意义。由于交互作用的P值较低,可知处理效应在各行(本示例中为各性别)上并不相同。事实上,在本示例中,该处理对男性和女性产生了相反的效果。因此,询问总体平均处理效应毫无意义。
行因素 P 值
零假设是,总体中每行(完全忽略列)的均值相同,且我们观察到的行均值之间所有差异均由随机因素造成。 在上例中,行代表性别,因此零假设是男性和女性的平均反应相同。P值回答了这个问题:如果零假设成立,随机获得的行均值差异(或更大差异)与实际观察到的差异相等的概率是多少?
在上述两个例子中,行因素(性别)的P值都非常低。
数据汇总表
结果表中的这一小节提供了以下内容的摘要:
•列数(列因子)
•行数(行因素)
•值的数量
请注意,若通过“因子名称”选项卡为列因子和行因素输入描述性名称,这些名称将显示在数据汇总表中。此功能是 Prism 8.2 版本中针对普通双因素方差分析新增的。
多重比较检验
请注意,双因素方差分析生成的三个 P 值并未针对这三组比较进行校正。虽然这样做似乎合乎逻辑,但在方差分析中传统上(甚至从未?)进行过此类校正。
多重比较检验是统计学中最令人困惑的主题之一。由于 Prism 为单因素方差分析和双因素方差分析提供了几乎相同的多重比较检验方法,因此我们已将相关信息整合在一起。
参考文献
大卫·J·谢斯金。《参数与非参数统计方法手册:第三版》ISBN:1584884401。