当您最关注的参数并非由单一数据集决定,而是由两个数据集之间的关系决定时,全局拟合最为有用。
示例数据
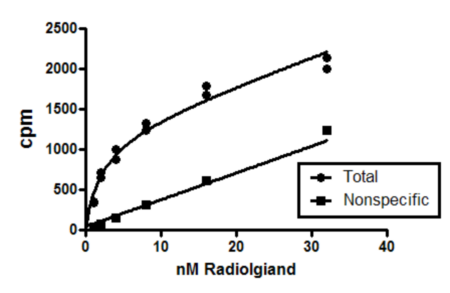
选择 XY 数据集:结合 - 饱和结合(针对总结合与非特异性结合)
使用非线性回归拟合数据,打开“结合 - 饱和”方程列表,并选择“单位点 - 总结合与非特异性结合”。您将看到如下所示的拟合结果。
方程说明与全局拟合
本实验通过测量不同浓度放射性配体在受体上的平衡结合情况,以确定该放射性配体的Bmax和Kd值。由于配体既会结合目标受体,也会结合非特异性位点,因此实验同时测定了总结合量和非特异性结合量(即在过量未标记受体拮抗剂存在下放射性配体的结合量)。
此类数据通常通过先从总结合量中减去非特异性结合量来分析。随后,所得的特异性结合量将用于拟合描述单个受体位点平衡结合的模型。
全局拟合可同时拟合总结合和非特异性结合量,无需先将两组数据集相减。唯一的技巧在于编写一个模型,使不同方程分别拟合每组数据集。Prism的内置方程设置如下:
specific=Bmax*X/(X+Kd)
nonspecific=NS*X + Background
<A>Y=specific+nonspecific
<B>Y=nonspecific
第一行定义了特异性可饱和结合。
第二行将非特异性结合定义为添加的放射性配体(X)的固定比例加上背景值(通常为零)。
第三行前带有 <A>,因此仅适用于第一个数据集(A 列,总结合)。它将该数据集中的 Y 值定义为总结合与非特异性结合量的总和。
第四行前带有 <B>,因此仅适用于第二个数据集,并定义该数据集中的 Y 值等于非特异性结合。
该方程的定义包含一个约束条件:参数 NS 和 background 在两个数据集之间共享。这样,Prism 就能基于对两个数据集的拟合,找到 NS 和 background 的控制数据。由于 Bmax 和 Kd 仅用于拟合第一个数据集,因此共享这些参数没有意义。
您关注的参数(Bmax 和 Kd)无法仅通过拟合单个数据集来精确确定。但通过拟合一个同时定义两个数据集(及其相互关系)且在数据集间共享 NS 参数的模型,Prism 能够从数据中获取尽可能多的信息。