下图显示了两条剂量反应曲线。该实验的目的是确定两个EC50值。EC50是指能引起介于最小反应和最大反应之间一半反应程度的浓度(剂量)。下图中的每条曲线都是分别拟合自其中一组数据集。水平线表示EC50的95%置信区间。
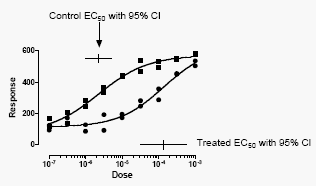
虽然曲线很好地拟合了数据点,但置信区间却相当宽。我们实际上并未以足够精确的程度确定 EC50,因此无法得出有用的结论。问题在于,控制数据(方块)并未真正界定曲线的底部平台,而处理组数据(圆圈)也未能真正界定曲线的顶部平台。 由于数据未能很好地界定最小和最大响应值,因此也无法清晰界定最小与最大响应值之间的中点。相应地,每个EC50的置信区间跨度超过了一个数量级。该实验的全部目的本在于确定这两个EC50值,但控制数据的不确定性已超出可接受范围。
通过共享参数可以解决这个问题。在本示例中,共享定义上下平台及斜率的参数。但不要共享EC50值,因为控制数据和处理数据的EC50值显然不同。
以下是结果。
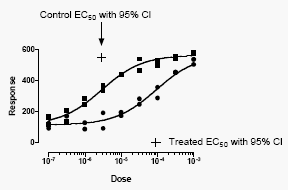
曲线图看起来仅有细微差异。但现在程序能够以极高的置信度找到最佳拟合参数。EC50值的95%置信区间跨度约为2倍(相比之下,未共享参数时跨度为10倍或更多)。
控制数据很好地界定了曲线的顶部,但未能界定底部。处理组数据很好地界定了曲线的底部,但未能界定顶部。通过同时拟合这两个数据集并共享部分参数,两个EC50值均以合理的确定性被确定。