什么是依赖度?
当模型包含两个或更多参数时(这种情况几乎总是存在),这些参数可能会相互关联。
参数之间存在相互依赖意味着什么?拟合模型后,改变其中一个参数的值,但保持其他参数不变。此时曲线会偏离数据点。现在,尝试通过调整其他参数,使曲线重新靠近数据点。如果能够使曲线更接近数据点,则说明这些参数之间存在相互依赖;如果能够将曲线恢复到原位置,则说明这些参数是冗余的。
Prism 可以通过报告相关矩阵或依赖度来量化参数之间的关系。
解读依赖度
您无需深入了解其计算原理即可解读依赖度。若您对该值的计算方法感兴趣,请继续阅读。
依赖度计算示例
本示例为指数衰减(摘自《MLAB应用手册》第128-130页,www.civilized.com。
时间 信号 1.0 39.814 2.0 32.269 3.0 29.431 4.0 27.481 5.0 26.086 6.0 25.757 7.0 24.932 8.0 23.928 9.0 22.415 10. 022.548 11. 021.900 12. 020.527 13.0 20.695 14. 020.105 15. 019.516 16. 019.640 17. 019.346 18. 018.927 19. 018.857 20. 017.652 |
|
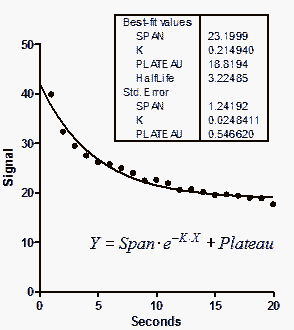
我们将重点关注速率常数 K。控制数据为 0.2149 s⁻¹,对应的半衰期为 3.225 秒。其标准误差为 0.0248 s⁻¹,对应的 95% 置信区间为 0.1625 至 0.2674 s⁻¹。
显然,这三个参数并非完全独立。若强行将 K 设为更高值(衰变更快),曲线将与数据点越发偏离。但可以通过让曲线起始值更高、终点值更低(即增大 Span 并减小 Plateau)来稍作补偿。各参数的标准误差值彼此依赖度较高。
将Span和Plateau固定在其控制数据上,并让Prism仅拟合速率常数K。当然,这不会改变最佳拟合值,因为我们已将Span和Plateau固定在其控制数据上。但K的标准误差现在更低,为0.008605。这合乎逻辑。 当固定Span和Plateau时,K值的变化对拟合优度(平方和)的影响,比允许Span和Plateau的值随之变化以补偿K值变化时更大。
当固定其他参数时,K 的标准误差值较低,这表明 K 的不确定性取决于其他参数。我们需要通过计算依赖度来量化这一关系。
在比较这两个标准误差值之前,我们需要先解决一个小问题。计算标准误差时,程序会除以自由度(df)的平方根。对于每次拟合,df等于数据点数减去回归拟合的参数数。因此,对于完整拟合,df等于20(数据点数)减去3(参数数),即17。 当我们将 Plateau 和 Span 的值固定时,仅有一个参数,因此 df=19。由于自由度不一致,这两个标准误差值无法直接比较。在其他参数被固定时计算出的标准误差值被人为压低了。这很容易修正。只需将两个参数受约束时报告的标准误差值乘以 19/17 的平方根。修正后的标准误差值为 0.00910。
现在我们可以计算依赖度。它等于1.0减去两个(修正后)标准误差值之比的平方。因此,本示例的依赖度等于1.0-(0.0091/0.0248)²,即0.866。本质上,这意味着K的方差中有86.6%源于其与其他参数的交互作用。
每个参数都有其独特的依赖度(除非只有两个参数)。Span的依赖度为0.613,Plateau的依赖度为0.813。
依赖度概念的起源
似乎没有文献可引述关于依赖度首次使用的记载。依赖度这一概念显然是由美国国立卫生研究院(NIH)的 Dick Shrager 提出的,随后由 Gary Knott 加以完善。MLAB 是首个计算依赖度的软件,其手册对此有详细说明。GraphPad Prism 只是按照手册中的说明实现了该方法。(我是在 2007 年收到 Gary Knott 的一封电子邮件中了解到这段历史的)。 以下是一篇早期论文,其中讨论了依赖度的基本概念,但其定义有所不同(取值范围为1到无穷大,而非0到1,且数学推导未作充分说明)。