引言
同源结合实验是指标记配体与未标记配体对受体的亲和力完全相同的一种实验。通常这是因为两者在化学结构上完全一致。通过分析不同浓度的未标记配体与一种(或更理想地,两种)浓度的标记配体之间对受体的竞争情况,可以确定受体的数量及其亲和力。
分步操作
创建一个 XY 数据表。将未标记化合物的浓度对数输入 X 轴,将结合量输入 Y 轴。将标记配体的浓度(单位为 nM)作为列标题。若使用两种不同浓度的标记配体,将获得更佳结果。
若有多个实验条件,请将第一个条件置于 A 列,第二个置于 B 列,依此类推。使用子列输入重复实验数据。
从数据表中,点击“分析”,选择“非线性回归”,选择“竞争性结合方程”面板,并选择“单位点 - 同源”。
模型
ColdNM=10^(x+9) ;低温浓度(单位:nM)
KdNM=10^(logKD+9) ;Kd(单位:nM)
Y=(Bmax*HotnM)/(HotnM + ColdNM + KdNM) + Bottom
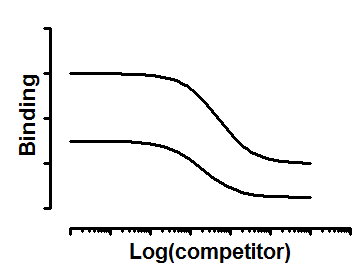
参数解读
logKd 平衡解离常数的对数。由于分析基于标记和未标记配体结合亲和力相同的假设,logKd 适用于配体的两种形式。
Bmax 是配体与受体结合的最大值(单位为 cpm)。该值代表与所有受体的结合总量,因此高于曲线的顶部平台。
NS 是非特异性结合的度量。它是 Y 轴单位下的底部平台值除以热标记配体的浓度(单位为 nM)。换言之,即热标记配体中非特异性结合的部分比例。
Prism 对曲线进行全局拟合,以从所有数据集中求得 logKd、Bmax 和 NS 的共同值
注释
该模型假设热配体和冷配体与受体的结合方式完全相同,且您使用两种浓度的热配体(分别位于 A 列和 B 列……)并改变冷配体的浓度。该模型假设所添加配体中只有一小部分会结合,因此游离浓度接近您添加的浓度。