1. 创建数据表
在“欢迎”或“新建表格”对话框中,选择创建 XY 数据表,选择使用教程数据,并在药理学教程集合中选择示例数据“剂量-反应:通过全局拟合进行 EC50 位移”。
2. 检查数据
示例数据可能被一个浮动注释部分遮挡,该注释说明了如何拟合数据(供未阅读本帮助页面的用户参考)。您可以将浮动注释移开,或将其最小化。
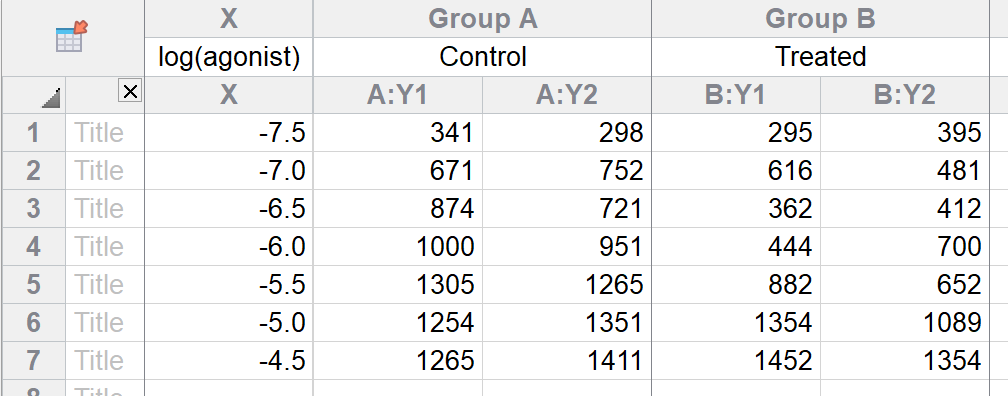
X 值为激动剂浓度的对数。请注意,“1e-9”与 0.000000001 完全相同。若要输入对数,请输入“-9”。
Y 值为两种条件下的响应值,每种条件各两次。
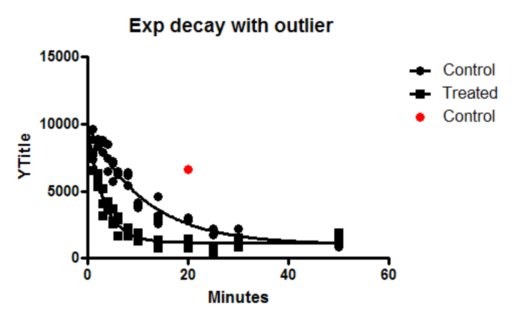
3. 查看图表
由于这是您首次查看该图,Prism 将弹出“更改图表类型”对话框。请选择第一个选项(绘制均值和误差线),并选择“标准差误差线”。
4. 选择非线性回归
单击 ,然后从 XY 分析列表中选择“非线性回归”。
,然后从 XY 分析列表中选择“非线性回归”。
或者,点击非线性回归的快捷按钮。

5. 选择模型
在非线性回归对话框的“拟合”选项卡中,转到“剂量-反应-刺激”模型,然后选择:log(激动剂) 与反应值 - 变量斜率。
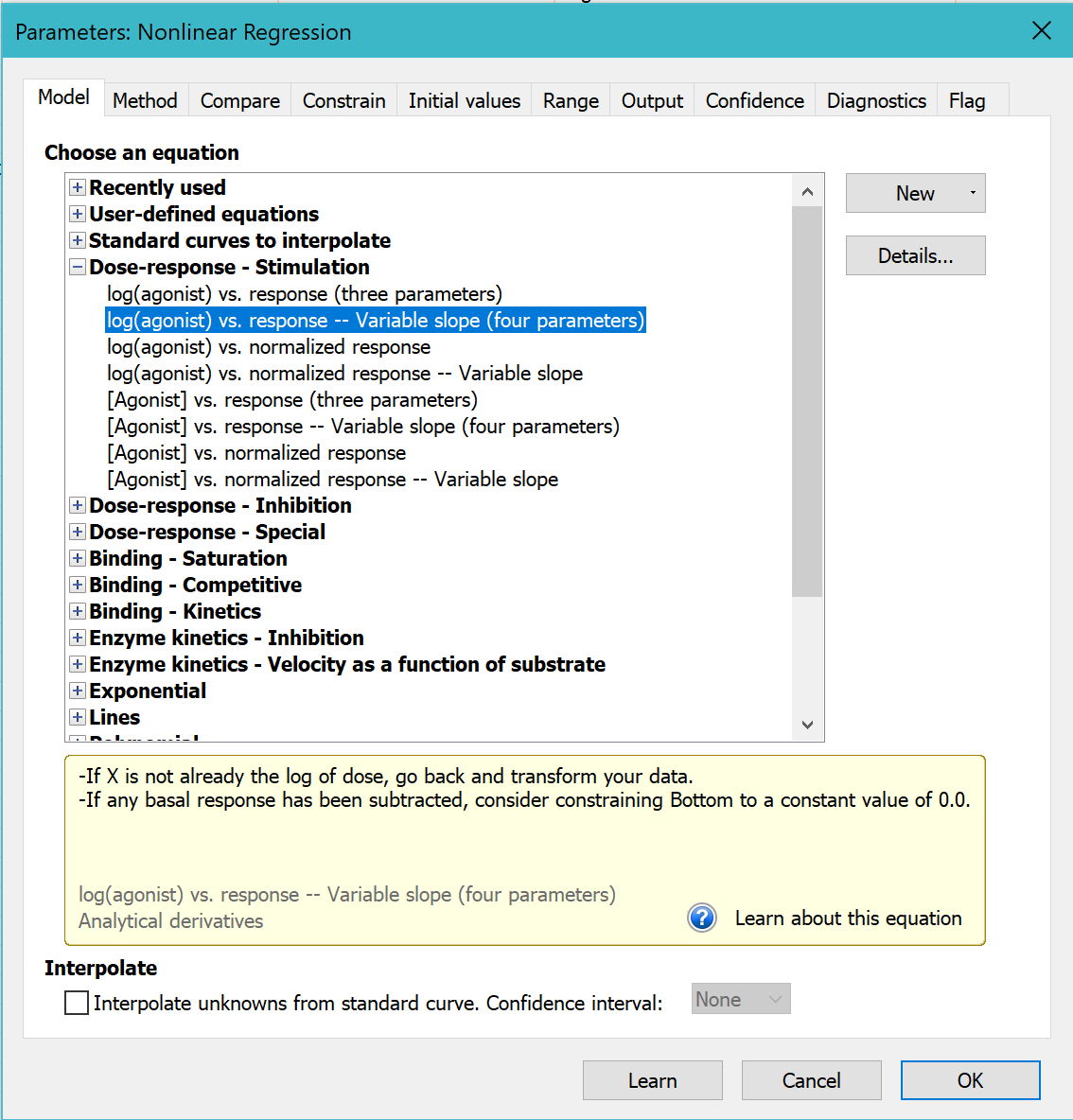
目前,请将其他所有设置保留为默认值。
点击“确定”即可在图表上叠加显示这些曲线。
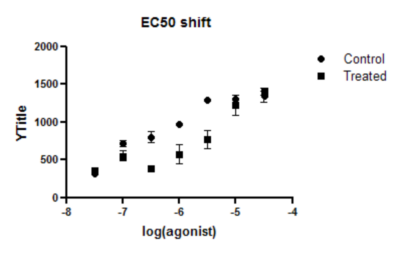
6. 检查结果
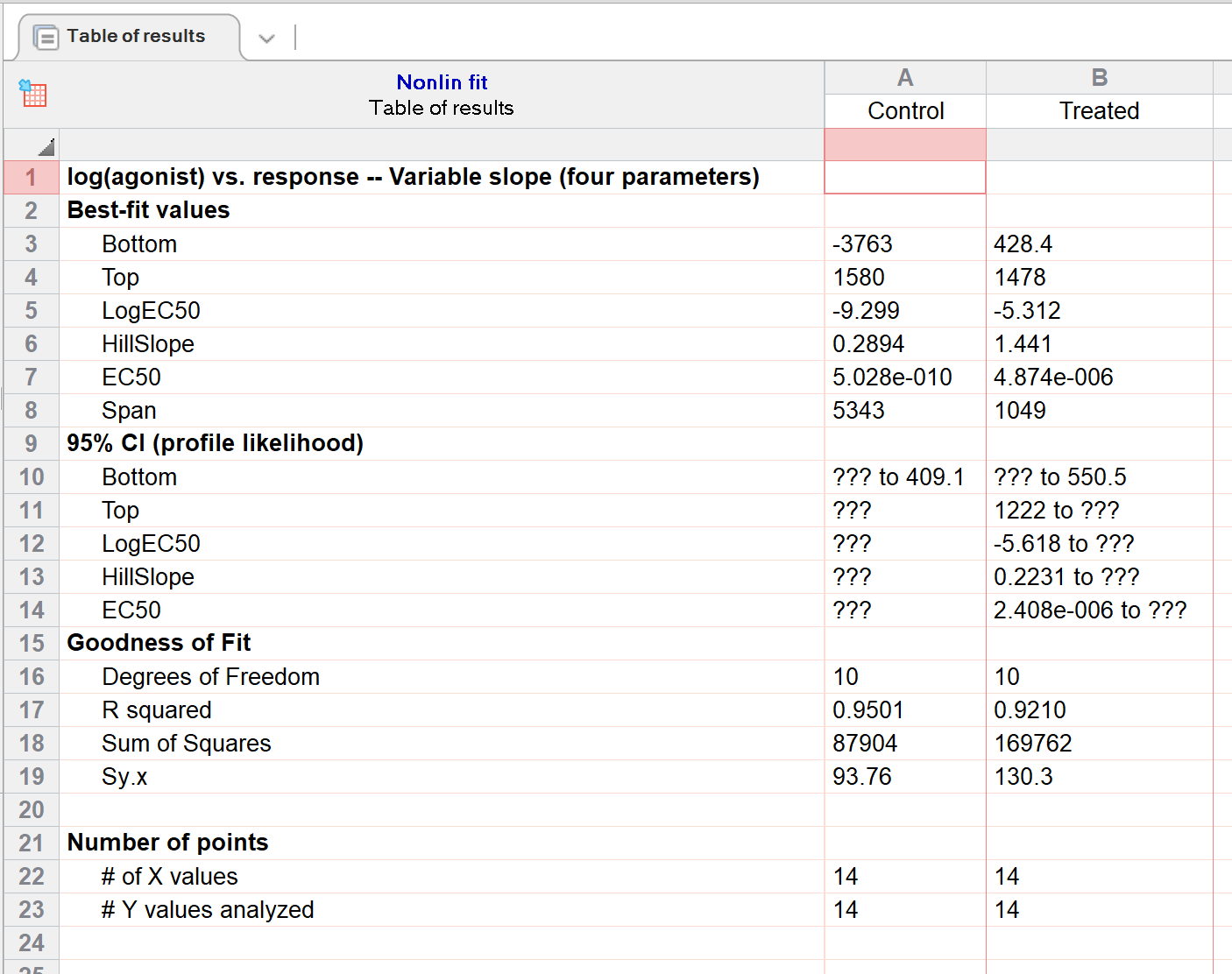
在“控制组”的结果中可以看出,虽然确定了一些最佳拟合估计值,但无法计算出95%置信区间。 “处理组”的结果情况稍好一些,因为对于每个最佳拟合估计值,都能计算出上置信限或下置信限(但没有任何一个最佳拟合估计值拥有完整的95%置信区间)。因此,解读这些结果时应格外谨慎。
Prism无法为这些最佳拟合参数计算完整的95%置信区间,原因是数据未能充分定义曲线(例如,控制数据未能定义曲线的底部平台)。EC50是指在曲线底部平台与顶部平台之间产生中等反应浓度的浓度。如果无法准确定义底部平台,则也无法确定EC50。
7. 返回对话框,并分享三个参数
如果您愿意假设在对照组和处理组条件下,顶部和底部的平台期以及斜率是相同的,那么您可以从这组数据集中获得更好的结果。换句话说,您假设处理会改变 EC50,但不会改变基础反应、最大反应或Hill斜率。
点击结果表左上角的按钮,返回非线性回归对话框。

转到“约束”选项卡,选择共享“底部”、“顶部”和“坡度”的值。当您共享这些参数时,Prism 会对数据集进行全局拟合,以求得“底部”、“顶部”和“坡度”的单一最佳拟合值(适用于两个数据集),并分别求得 logEC50 的最佳拟合值。
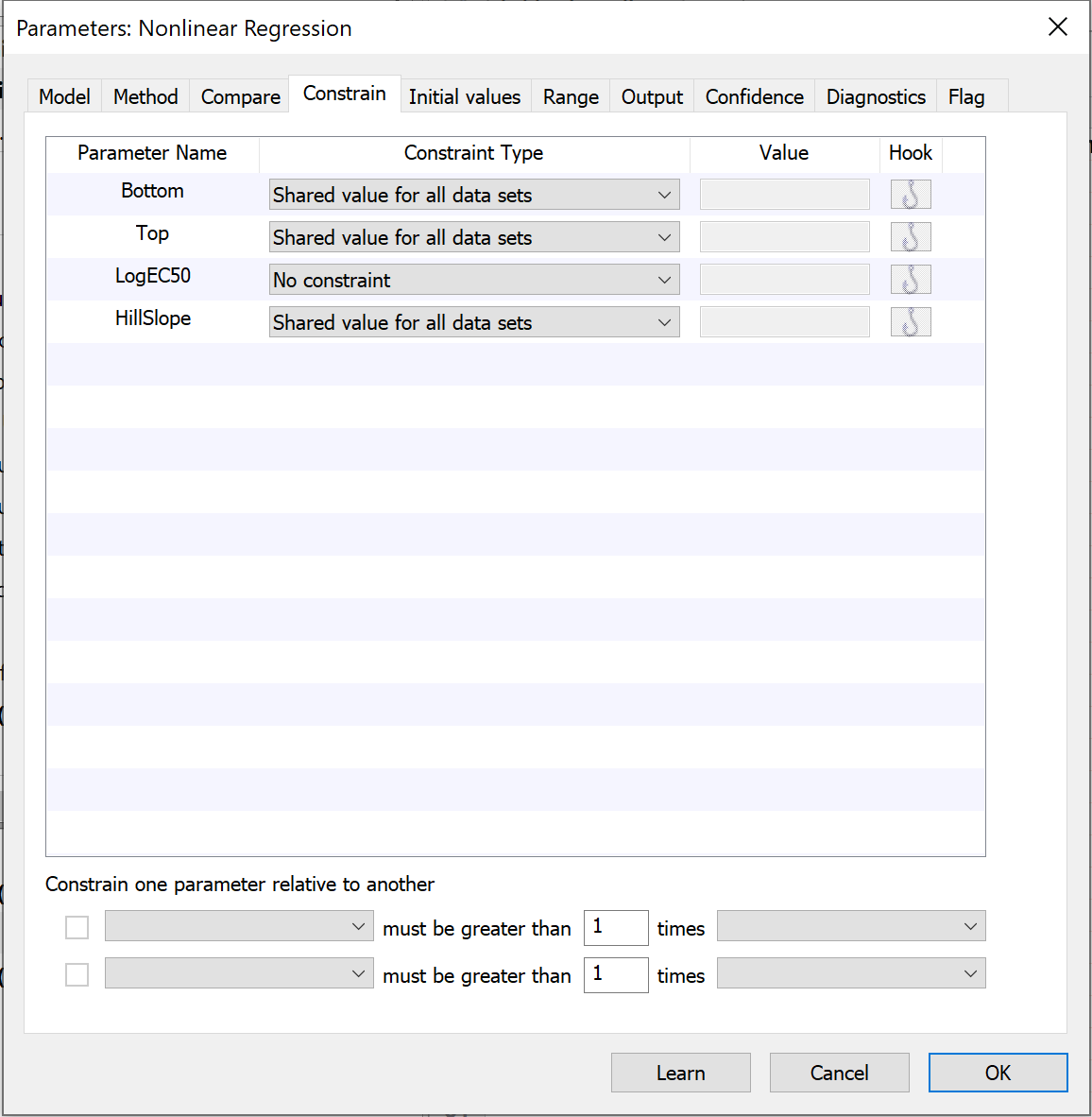
8. 查看修订后的图表和结果
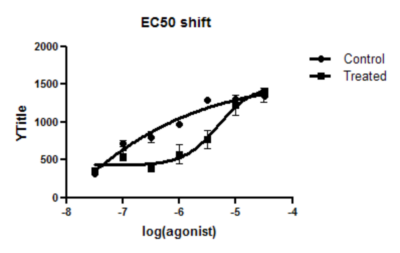
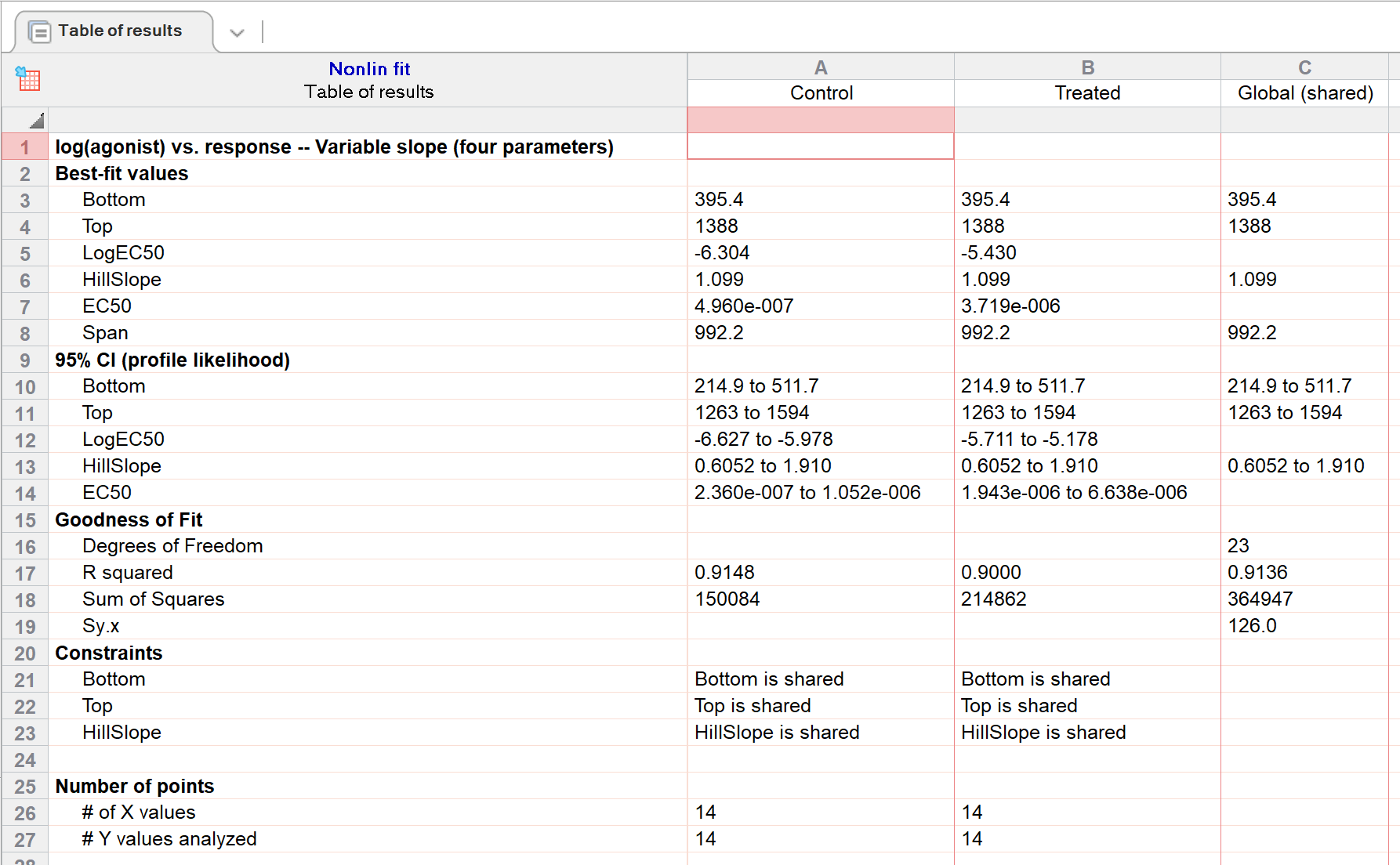
采用这种参数共享方法,置信区间会更窄。
9. 对两个 logEC50 值进行统计学比较
返回非线性回归的参数对话框,转到“比较”选项卡。选择该选项以检验所选的非共享参数在数据集之间是否存在差异。确保已选中“额外平方和F检验”,然后勾选“LogEC50”旁边的复选框。
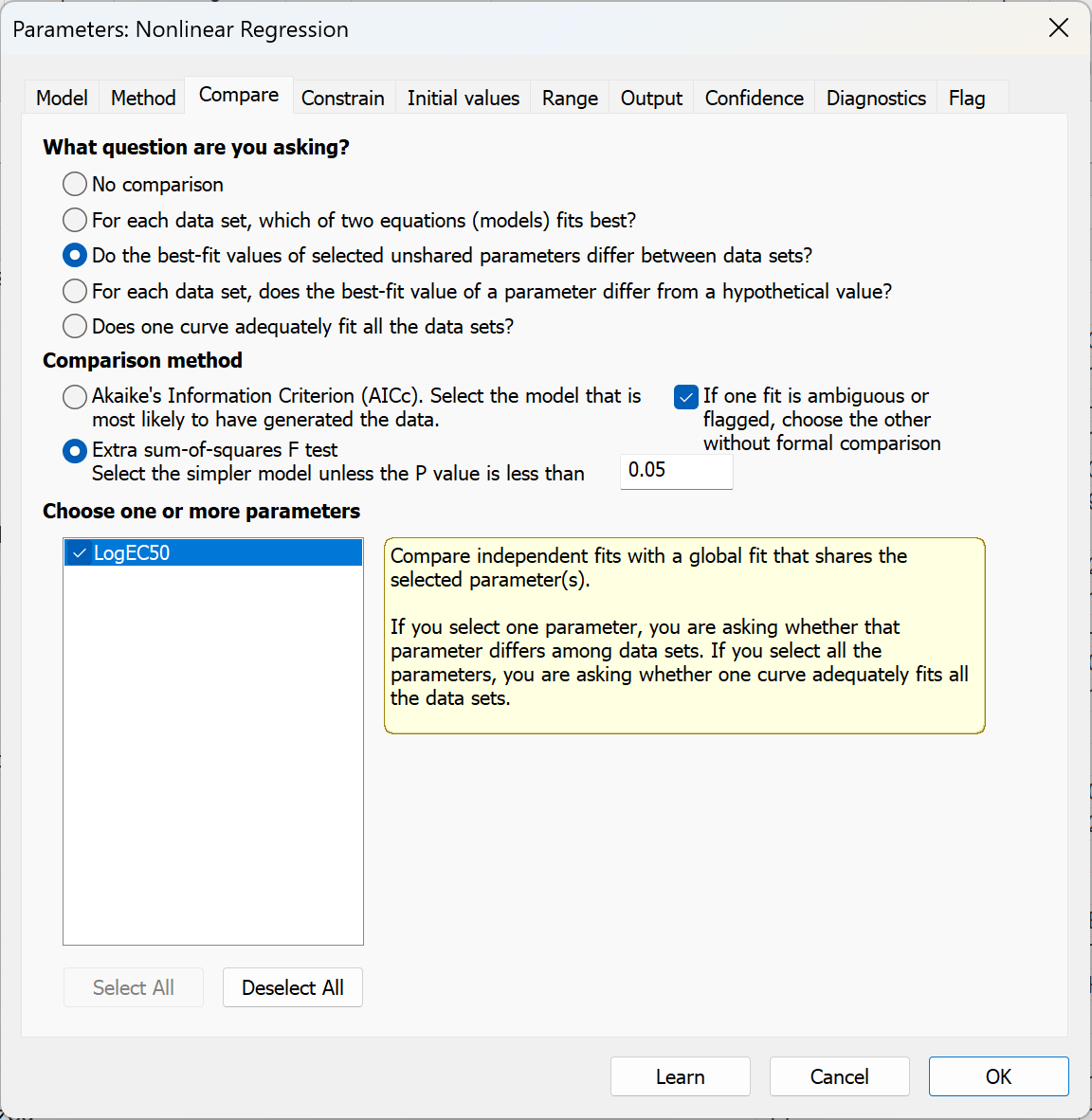
Prism 现在将通过两种方式拟合数据:
1.为每个数据集分别设定 LogEC50 参数进行拟合。这与上一步的拟合方式相同,并将继续共享分析对话框“约束”选项卡中定义的“顶点”、“底点”和“斜率”参数。
2.共享所有参数(包括 LogEC50)。与第一种方法类似,其中三个模型参数原本已共享。由于在此第二次拟合中所有四个参数均被共享,Prism 将通过所有数据拟合一条曲线,而忽略数据所属的处理组。它通过额外平方和F检验,比较平方和(实际上是平方和的平方和,因为每种情况下都拟合了两个数据集)。 结果显示在结果表的顶部。

由于 P 值极小,因此我们拒绝“总体中两个 LogEC50 值相等”的零假设,并得出结论:这两个 LogEC50 值不同。
请注意,由于所有参数均被共享,您本可在分析参数对话框的“比较”选项卡中选择“一条曲线能否充分拟合所有数据集?”这一选项。在这种情况下,这两种比较方法将具有等效性(同样是因为所有参数均被共享),且比较结果将相同(尽管结果表中的表述会略有不同):

10. 直接拟合两个 IC50 值的比值
根据第 8 步的结果,您可以计算出您想要知道的 - 两个 EC50 值的比值。
但 Prism 可以直接计算此值。
返回分析参数对话框,在“拟合”选项卡中,从“剂量反应方程 - 特殊”方程组中将方程更改为“EC50 偏移”。接受所有默认设置并点击“确定”。由于模型等效,图形将保持不变。但现在,Prism 不再仅拟合两个 logEC50 值,而是同时拟合其中一个值及其比值。
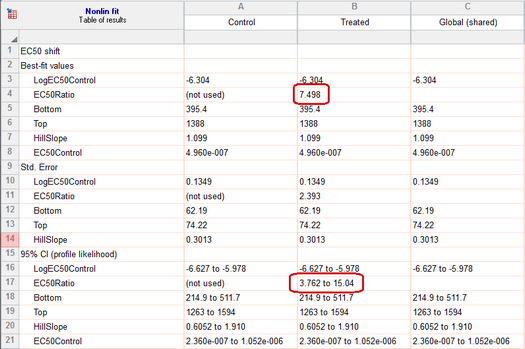
该方程的设计正是为了满足本示例的需求。请阅读关于该方程的构建过程,以便在必要时能够自行构建方程。