什么是列常数?
当您同时拟合多个数据集时,可以将列标题用作第二个独立变量。我们将这种将参数限定为列常量的做法称为“列常量”。通过示例可以更清楚地理解这一点。
如何输入列常量?
要了解列常量的运作原理,请使用示例数据文件“酶动力学 - 竞争性抑制”创建一个新的XY表格。
该数据表包含一个 X列和四个 Y 列,每列代表不同浓度的抑制剂。抑制剂浓度以列标题形式输入。
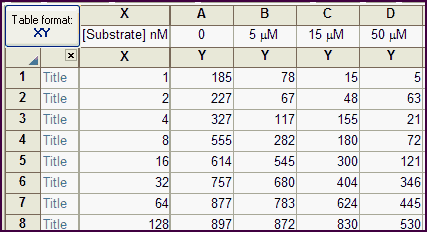
请注意,Prism 仅读取列标题中的数值。在本示例中,单位虽指定为微摩尔,但 Prism 会忽略该单位信息,仅读取数值本身,不会进行任何单位转换。
拟合数据时指定列常数
选择初始值时,请从下拉列表中选择“列标题值的均值”或“log(列标题值的均值)”。

示例
要拟合上述样本数据,请点击“分析”,选择“非线性回归”,选择“酶动力学”方程面板,并选择“竞争性酶动力学”。方程已内置,但若点击“详细信息”按钮,即可查看其数学表达式。
KmObs=Km(1+[I]/Ki)
Y=Vmax*X/(KmObs+X)
第一行定义了一个中间变量(KmObs,即存在竞争性抑制剂时的观测米氏常数),它是酶的米氏常数(Km)、抑制剂浓度(I)和竞争性抑制常数(Ki)的函数。
第二行将酶速率(Y)计算为底物浓度(X)和 KMapp 的函数。
该模型定义时将 I 约束为数据集常量,这意味着其值来自列标题。因此,在本示例中,拟合 A 列时 I=0,拟合 B 列时 I=5,以此类推。Prism 会忽略标题中的“μM” - 它不进行任何单位转换。
其余三个参数(Km、Ki 和 Vmax)被定义为共享参数,因此 Prism 拟合出的控制数据适用于整个数据集系列。

Prism 确定了无抑制剂条件下酶的最大速度(Vmax,单位与您输入的 Y 值相同)、无抑制剂条件下酶的米氏常数(Km,单位与 X 值相同)以及竞争性抑制常数(Ki,单位与列常数相同)。 请注意,I 并非待拟合参数,而是采用您在列标题中输入的常量值。KmObs 并非待拟合参数,而是用于定义模型的中间变量。
了解更多关于竞争性酶抑制的信息。
总结 - 列常数的优势
通过使用列常数和全局拟合(共享参数),本示例确定了一个参数(Ki),其值无法从任何单个数据集确定,而只能通过考察数据集之间的关系来确定。