下图展示了两组数据集,除了一个数据点外完全相同。显然,右侧的数据集有两个异常值,而左侧的数据集只有一个。这一结论显而易见。
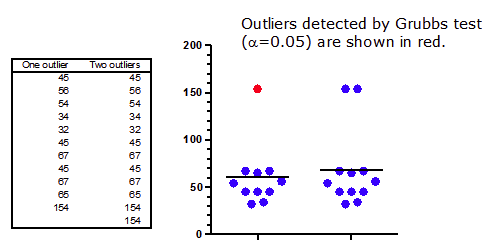
(下载 Prism 文件。)
Grubbs 异常值检验的结果令人惊讶。该检验(设显著性水平为 5%,但设为 1% 时结果相同)确实识别出了左侧数据集中的异常值。这并不意外。但 Grubbs 检验在右侧数据集中却未发现任何异常值。第二个异常值的存在阻碍了异常值检验发现第一个异常值。这种现象被称为掩蔽效应。
Grubbs 异常值检验通过计算可能的异常值与均值的差值,再将该差值除以标准偏差,从而得出 Z 比值。如果 Z 值足够大(考虑到样本量),则该点被判定为异常值。 请注意,均值和标准偏差是根据所有数据计算得出的,计算过程中包含疑似异常值。如下表所示,第二个异常值(在小数据集中)的存在会使标准偏差膨胀,从而导致 Z 值降至定义异常值的阈值以下。
左侧(一个异常值) |
右侧(两个异常值) |
|
均值 |
60.364 |
68.167 |
标准差 |
33.384 |
41.759 |
Z |
2.8048 |
2.0554 |
n |
11 |
12 |
定义异常值的临界Z值(α=5%) |
2.3547 |
2.4116 |
定义异常值的临界Z值(α=1%) |
2.5641 |
2.6357 |