单次 Prism 分析可对曲线进行平滑处理,并/或将曲线转换为其导数或积分。
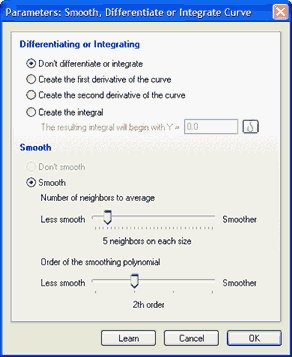
求曲线的导数或积分
一阶导数表示曲线在每个 X 值处的斜率。当曲线向上时,导数为正;当曲线向下时,导数为负。在曲线的峰值和谷值处,导数等于零。计算出数值导数后,如果您选择,Prism 可以对结果进行平滑处理。
二阶导数是导数曲线的导数。在曲线的拐点处,二阶导数等于零。
积分是曲线与 Y=0 直线(或您输入的其他值)之间累积的面积。
注:
•Prism 无法进行符号代数或微积分运算。如果您向 Prism 提供定义曲线的 XY 点序列,它可以根据该点序列计算数值导数(或积分)。但如果您向 Prism 提供一个方程,它无法据此推导出定义导数或积分的新方程。
•此分析对曲线进行积分,结果生成另一条显示累积面积的曲线。请勿将其与 Prism 中另一项计算曲线下面积单一值的分析混淆。
曲线平滑
如果您从仪器导入曲线,可能希望对数据进行平滑处理以改善图形的外观。由于平滑曲线会导致数据丢失,因此在进行非线性回归或其他分析之前,不应平滑曲线。
Prism 提供了两种调整曲线平滑度的方法。您可以选择用于求平均的相邻点数量以及平滑多项式的“阶数”。由于平滑的唯一目的是使曲线看起来更美观,您可以尝试几种设置,直到对结果的外观满意为止。如果设置值过高,某些峰值会被平滑掉而丢失;如果设置值过低,曲线则不够平滑。 最佳平衡点因人而异 - 请通过试错法来调整。
结果表的行数少于原始数据。
请勿分析平滑后的数据
对曲线进行平滑处理可能会产生误导。其核心思想是减少“模糊”部分,以便看清实际趋势。 问题在于,您可能会看到实际上并不存在的“趋势”。下图上排的三张图表是模拟数据。每个数值都来自一个均值为 50、标准偏差为 10 的高斯分布。每个数值都是独立地从该分布中抽取的,不考虑之前的数值。当您查看这三张图表时,会看到数据围绕一条水平线随机散布,这正是数据的生成方式。
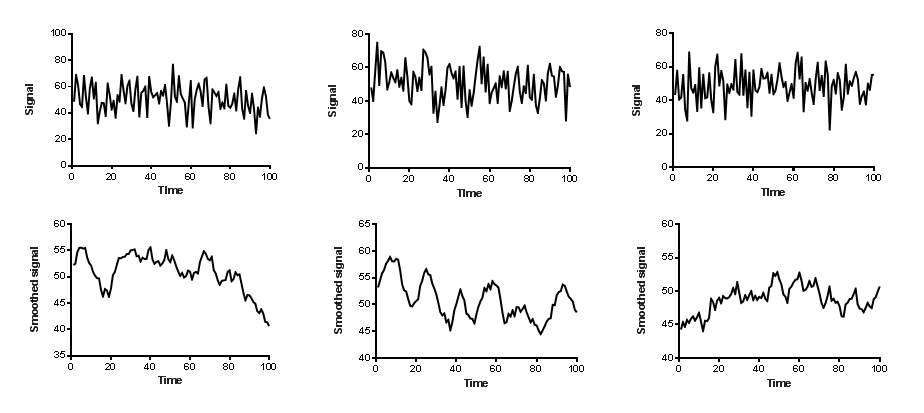
上图中的后三幅图表展示了经过平滑处理后的同一组数据(每侧取10个值的平均值,并使用二阶平滑多项式)。观察这些图表时,您会发现其中存在趋势。第一幅图呈现出下降趋势。第二幅图似乎以规律的方式波动。第三幅图则呈现上升趋势。所有这些趋势都是平滑处理产生的伪像。每幅图表展示的数据都与它上方的图表完全相同。
对数据进行平滑处理会放大任何向高值或低值的剧烈随机波动,同时削弱点与点之间的变异性,从而营造出趋势的假象。相关性、线性和非线性回归的一个关键假设是数据之间相互独立。而对于平滑后的数据,这一假设不再成立。 如果某个数值恰好极高或极低,经过平滑处理后,其相邻数据点也会呈现同样的极端值。由于随机趋势被放大而随机散布被弱化,因此对平滑数据进行的任何分析(若未考虑平滑处理这一因素)都将失去有效性。
数学细节
•一阶导数的计算方法如下(x 和 Y 为数据数组;x' 和 y' 为包含计算结果的数组)。
x'[i] = (x[i+1] + x[i]) / 2
y' at x'[i] = (y[i+1] - y[i]) / (x[i+1] - x[i])
•二阶导数通过运行该算法两次来计算,本质上是计算一阶导数的一阶导数。
•Prism 使用梯形法对曲线进行积分。结果中的 X 值与您正在分析的数据的 X 值相同。结果中的第一个 Y 值等于您指定的值(通常为 0.0)。对于其他行,所得的 Y 值等于前一个结果加上通过添加该点而增加的曲线面积。该面积等于 X 值之间的差值乘以前一个 Y 值与当前 Y 值的平均值。
•平滑处理采用 Savitsky 和 Golay 的方法 (1)。
•若要求 Prism 同时执行平滑处理并转换为导数(一阶或二阶)或积分,Prism 将按顺序执行这些步骤。首先生成导数或积分,然后进行平滑处理。
参考文献
1. A. Savitzky 和 M.J.E. Golay,(1964)。通过简化最小二乘法对数据进行平滑与求导。《分析化学》36 (8): 1627–1639