Navigation: 统计原理 > 异常值
建议:小心手动识别异常值
一种常见的做法是目测数据,然后手工去除异常值。这种方法的问题在于随意性。很容易保留那些有助于数据得出你想要的结论的点,而删除那些阻碍数据得出你想要的结论的点。
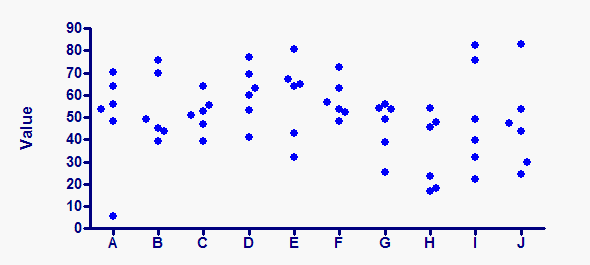
上图是通过模拟绘制的。所有十个数据集的数值都是从高斯分布中随机抽样的,均值为 50,标距为 15。但大多数人会得出结论,数据集 A 中的最低值是异常值。也许数据集 J 中的高值也是如此。大多数人无法欣赏随机变异,往往会过于频繁地发现 "异常值"。