Prism 提供了三种用于控制 FDR 的算法供用户选择。这三种算法的工作原理大致相同。
1.为每次比较计算一个 P 值。
2.将 P 值从低到高排序。
3. 从最大的 P 值开始。
4.为最大的 P 值计算一个阈值。该阈值依赖于所考察的 P 值数量。对于 Benjamini、Krieger 和 Yekutieli 的方法,阈值还依赖于该方法提供的真实零假设数量的估计值。
5. 如果该 P 值小于阈值,则所有 P 值均被标记为发现,操作结束。否则,继续。
6.转至第二大 P 值。
7.为第二大 P 值计算阈值。该阈值将小于最大 P 值的阈值。阈值的计算(见下文)依赖于 P 值的排名、P 值的数量,以及(对于 Benjamini、Krieger 和 Yekutieli 的方法)真实零假设数量的估计值(由该方法计算得出;无需您考虑)。
8. 如果该 P 值小于阈值,则该 P 值及所有更小的 P 值均被标记为发现,操作结束。否则继续。
9.转到下一个更低的 P 值。
10.计算该排名对应的阈值。该阈值将小于前一个阈值。
11. 如果 P 值小于该阈值,则该 P 值及所有更小的 P 值均被标记为发现,操作结束。否则重复步骤 9-10 直至完成。
这三种方法的区别在于阈值的计算方式。下表给出了详细说明,其中 Q 是期望的错误发现率(以百分比表示),N 是集合中的 P 值个数,Ntrue 是估计为真的零假设个数(属于下文的第二种方法)。定义 q 等于 Q/100。这将您输入的百分比值转换为分数。
方法 |
最小 P 值的阈值 |
最大 P 值的阈值 |
Benjamini 和 Hochberg 的原始方法 (1) |
q/n |
q |
Benjamini、Krieger 和 Yekutieli 的两阶段递升法 (2) |
q/[(1+q)Ntrue] |
[q/(1+q)] * (N / Ntrue) |
Benjamini 和 Yekutieli 的修正方法 (3) |
q/[N * (1 + 1/2 + 1/3 + ... + 1/N)] |
q /(1 + 1/2 + 1/3 + ... + 1/N) |
注:
•变量 q 定义为 Q/100,其中 Q 是您输入的期望错误发现率(以百分比表示)。
•最小值与最大值之间的 P 值阈值,通过这两端极值之间的线性插值确定。
•阈值以分数形式(而非百分比)计算,以便与 P 值进行比较。
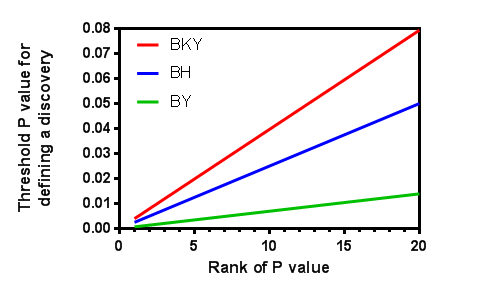
下图展示了分析 20 个 P 值(N=20)时的阈值,您设置 Q=5% 且 Ntrue=12(由 BKY 方法根据数据计算得出,仅适用于红色曲线)。 可以看出,Benjamini、Krieger 和 Yekuteili 的两阶段线性递升法(红色)具有最大的阈值,因此具有最高的检验力;而 Benjamini 和 Yekutieli 的修正方法(绿色)则具有最低的检验力。还可以看到,在计算最大 P 值的阈值时,这些方法的差异最大;而在计算较小 P 值的阈值时,它们则趋于一致。
参考文献
1.Benjamini, Y. & Hochberg, Y. 控制错误发现率:一种实用且具有强大检验力的多重检验方法。《皇家统计学会杂志》B辑(方法论)289–300 (1995)。
2.Benjamini, Y., Krieger, A. M. & Yekutieli, D. 《控制错误发现率的自适应线性递增法》。《生物计量学》93, 491–507 (2006)。我们采用该论文第6节中定义的方法,即两阶段线性递升法。
3.Benjamini, Y., & Yekutieli, D. (2001). 存在依赖度时多重检验中错误发现率的控制。《统计年鉴》,1165–1188。