只有当数据分析中的每一个步骤都完全按照计划执行,并作为实验设计的一部分被记录下来时,统计结果才能被字面意义上地解读。但在某些研究领域,这一规则常被打破。相反,分析往往如下所示:
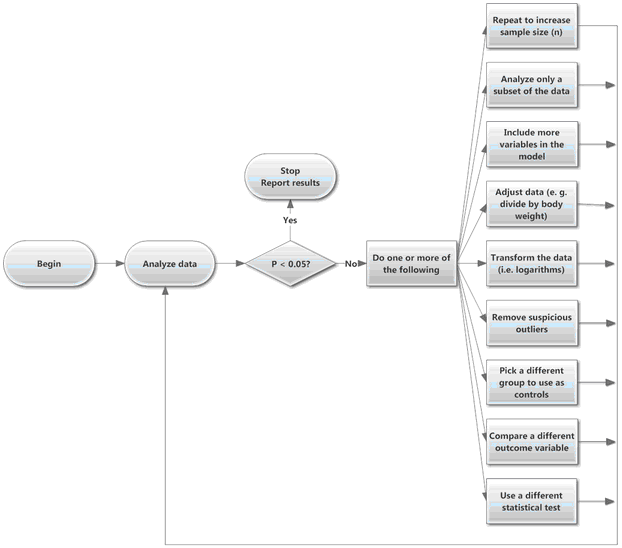
收集并分析一些数据。如果结果在统计学上不显著,但显示出与您预期方向一致的差异或趋势,那就再收集一些数据并重新分析。 或者尝试不同的分析方法:剔除几个异常值;进行对数转换;尝试非参数检验;通过标准化重新定义结果(例如除以每只动物的体重);采用一种在调整另一个变量差异的同时比较某个变量的方法;可能性不胜枚举。不断尝试,直到获得统计学显著的结果,或者直到资金、时间或好奇心耗尽为止。
通过这种方式收集到的数据结果不能仅凭表面价值来解读。即使实际上确实没有差异(或没有效应),得到“统计学显著”结果的概率仍超过5%。问题在于,当您仅在P值大于0.05时才选择收集更多数据(或采用不同的分析方法),就会引入偏倚。 如果首次分析中的P值小于0.05,那么在收集更多数据或采用替代分析方法后,该P值可能会大于0.05。但如果您仅在首次P值大于0.05时才收集更多数据或尝试不同的数据分析策略,您就永远无法察觉这一点。
“P-hacking”(P值操纵)这一术语由Simmons等人(1)提出,他们还使用了“研究者自由度过多”这一表述。这是一个涵盖动态样本量收集、HARKing等行为的通用术语。P值操纵主要分为三类:
•第一类P-hacking涉及改变实际值。例如:临时决定样本量、更换对照组(若对初始结果不满意且实验涉及两个或更多对照组)、尝试将不同自变量组合纳入多元回归(无论选择是手动还是自动)、分别对包含或排除异常值的数据进行分析,以及分析数据的各种子组。
•第二种P-hacking是使用不同的统计检验对同一数据集进行重新分析。例如:尝试参数和非参数检验;先分析原始数据,然后尝试分析数据的对数。
•第三种P-hacking是“岔路花园”(2)。这种情况发生在研究者基于其假设和数据进行了合理的分析,但如果数据结果不同,他们本会进行其他同样合理的分析。
探索数据是提出假设并得出初步结论的极佳途径。但所有此类分析都需明确标注,并使用新数据进行重新验证。
参考文献
1.Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). 假阳性心理学:数据收集与分析中未披露的灵活性使得任何结果都能被呈现为显著。《心理科学》,22(11),1359–1366。
2.Gelman, A., & Loken, E. (2013). 《岔路花园:为何多重比较可能成为问题,即使不存在“钓鱼式研究”或“P-hacking”,且研究假设是预先设定的》。截至2016年1月尚未发表