当回归模型中包含一个分类变量作为预测因子时,Prism 会自动使用 "变异性虚拟编码 "对该变量进行编码。这一过程(在幕后)生成的新变量数量等于原始分类变量的级数减一。换句话说,如果一个分类预测因子变量有 5 个独特的级别(例如 A、B、C、D 和 E),虚拟编码将生成 4 个新变量。如果一个分类预测因子变量只有两个独特的层级(例如男性和女性),虚拟编码只会产生一个新变量。这样,除一个变量外,分类预测因子变量的每个层次都会得到一个新变量,用于回归分析。此外,每个新变量都会计算出一个贝塔系数。
但这些贝塔系数代表什么呢?没有得到新变异性的水平又如何呢?这些问题都与分类预测因子变量的参考水平概念有关。
什么是参考水平
分类预测因子变量的参考水平通常被认为是给定变量的 "基线 "或 "通常 "观察值。在虚拟编码过程中,参考水平的变异性会被省略,因为每个观测值都会包含 "0"。相反,参考水平被用作解读生成的回归模型的一种手段。让我们用一个本示例来说明这一点:
考虑一个包含分类预测因子 "性别 "的模型,其水平为 "男性 "和 "女性"。如果 "女性 "是我们的参考水平,那么预测模型将包含 "男性 "的贝塔系数,但不包含 "女性 "的贝塔系数。在这种情况下,"男性 "的贝塔系数告诉我们的是,在所有其他变量不变的情况下,预测结果变量在男性和女性之间的变异性有多大。换句话说,如果 "男性 "的贝塔系数是-5.632,那么(在所有其他变量不变的情况下),预测男性的结果变量比女性小 5.632。
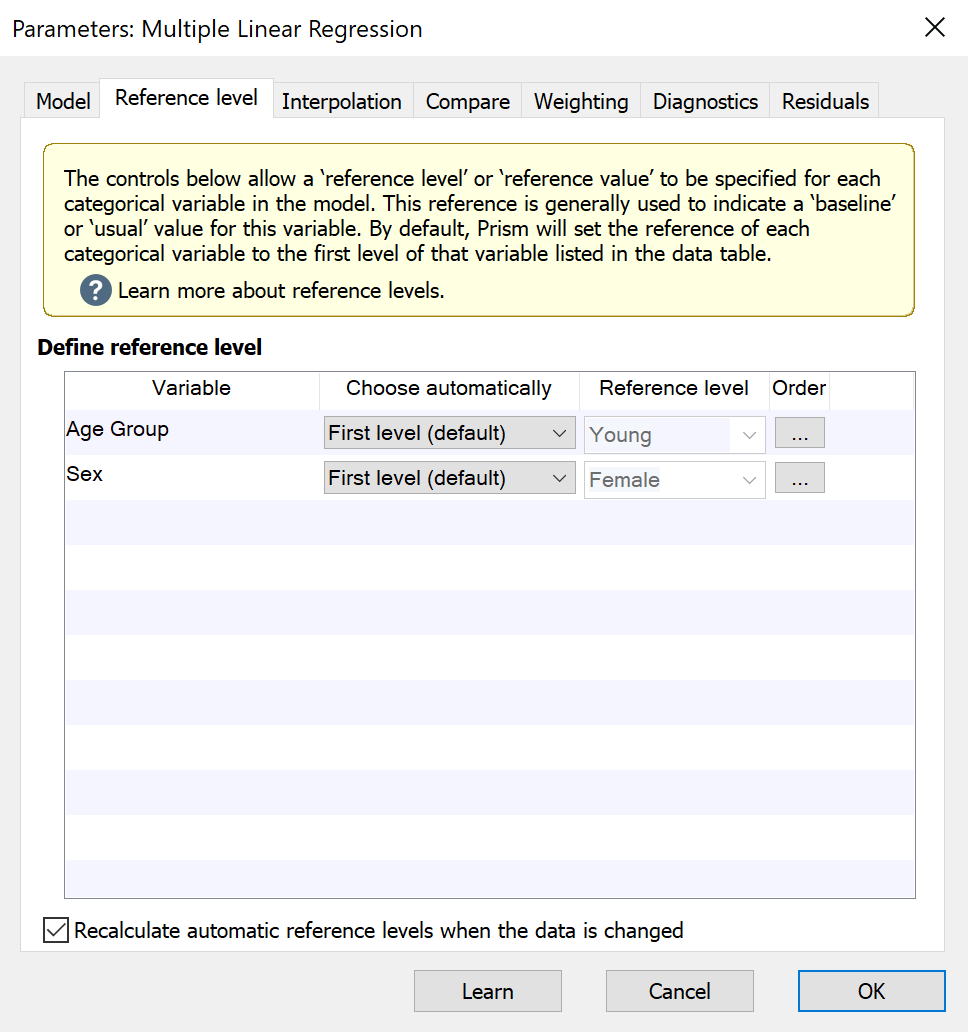
如何指定参考水平
在参考水平选项卡上,回归模型中包含的每个分类预测因子变量都将列在 "定义参考水平" 下。对于每个变异性变量,您可以选择自动定义参考水平或手动定义水平。Prism 提供了多种根据数据表中的数据自动指定参考水平的方法。这些方法包括
•第一级(默认)。这将选择数据表中变量的第一级。请注意,如果数据表中行的顺序发生变化,参考层也会随之变化!
•最后一级。这将选择数据表中变量的最后一级。请注意,如果数据表中行的顺序发生变化,该参考层级也会发生变化!
•最频繁级别。如果您希望回归系数提供罕见水平与常见水平的比较信息,则可以使用此选项。请注意,更改数据表中行的顺序不会导致此参考水平发生变化。但是,添加或删除数据可能会导致参考水平发生变化(通过改变每个水平的频率)。
•频率最低的层级。这将确定变异性中最频繁出现的层级,并将其选 为参考层级。请注意,更改数据表中行的顺序不会导致参考层级发生变化。但是,添加或删除数据可能会导致参考水平发生变化(通过改变每个水平的频率)。
对于上述每种自动方法,对数据的某些更改(组织或添加/删除数据)可能会导致指定的参 考级别发生变化。但是,如果您想让 Prism 自动确定参考水平,但防止它随数据的变化而变化,可以使用复选框 "当数据发生变化时重新计算自动参考水平"。
最后,您还可以在第一个下拉菜单中选择 "自定义......",然后在第二个下拉菜单中选择所需的 参考水平,从而指定自定义参考水平。
更改结果中分类变量水平的顺序
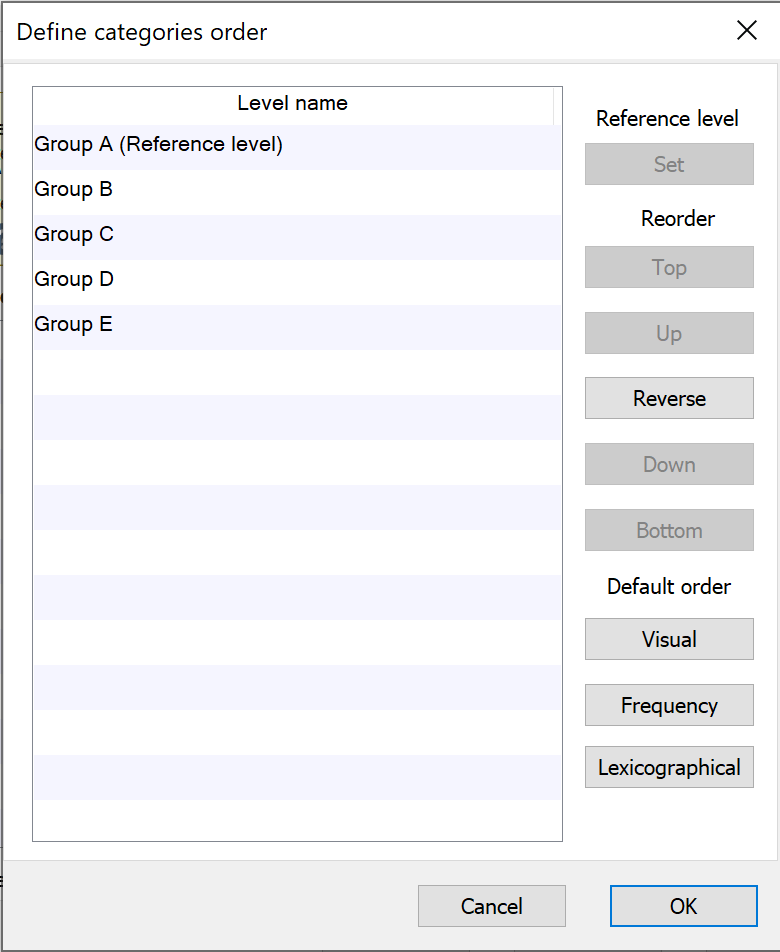
在生成回归分析结果输出时,Prism 会按照分类预测因子变量在数据表中出现的顺序显示它们的 级别。不过,为了便于演示或发表,有时可能需要更改回归模型中一个或多个特异性分类预测变量的 级别顺序。通过 "定义参考水平 "部分的 "顺序 "按钮,可以分别自定义每个分类变量的水平顺序。通过 "定义类别顺序 "子菜单中的控件,您可以
•将分类变量的参考层级设置为当前选择的层级
•手动重新排列层级(顶部、上部、反向、下部和底部控件)
•使用三种默认方法之一重新排列层级:
o视觉顺序:各层次在数据表中首次出现的顺序
o频率:频率越高的级别在顺序中出现的越靠前
o词典顺序:使用词典顺序排列。类似于字母顺序,但请注意,名为 "a100 "的数据级将排序在 "a90 "之前,因为 "1 "在 "9 "之前。这种排序不考虑整个数字 "100 "大于整个数字 "90 "的情况。
如果输入数据发生变化,参考水平会发生什么变化?
默认情况下,分类变量的参考水平被选择为数据表中该变量的第一个水平。Prism 还提供其他自动选择,包括 "最后一级"、"最频繁级 "和 "最不频繁级"。但是,如果输入数据发生变化(或输入数据表中添加了其他数据),这些自动选择中的某些也会发生变化。要确保在输入数据更改或添加附加数据时指定的参考水平不会更改,可以取消选中 "数据 更改时重新计算自动参考水平 "旁边的复选框,或者使用相应的下拉菜单将各个参考水平集 设为 "自定义..."。