逻辑模型拟合过程回顾
将逻辑回归模型拟合到一组数据的过程,涉及确定模型参数的一组“控制数据”。其工作原理是使用迭代算法来最大化逻辑回归模型的似然函数。 可以这样理解这一过程:它试图找出“最有可能”产生观测数据的模型参数值。这引出了几个重要概念。首先,这意味着 - 一般而言 - 逻辑回归模型在拟合(或分类)输入数据方面的表现,通常会优于其对新数据结果的准确预测性能。
使用该方法的另一个含义是,在某些情况下,算法无法确定参数值,因此无法定义逻辑回归模型。逻辑回归中出现这种情况的三个常见情形包括:完全分离、准完全分离以及X变量的线性依赖度。
完全分离
完全分离(有时也称为完美分离)是指模型能够完全预测数据的情况。 换言之,对于给定的预测因子(或其线性组合),当该因子值高于某个阈值时,总是出现一种结果;当该因子值低于该阈值时,总是出现另一种结果。这听起来可能有些令人困惑,但在实践中,这意味着模型会将所有输入值为0的点正确分类为负结果,并将所有输入值为1的点正确分类为正结果。 乍看之下,这似乎不是什么大问题,因为逻辑回归的目标之一正是对观测结果进行分类。然而,逻辑回归的另一个目标是寻找模型参数的最佳拟合估计值。完全分离的问题在于,在这种情况下,不存在能最大化似然函数的唯一控制数据集。让我们看一个简单的例子:
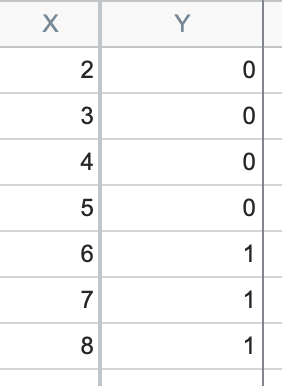
可以看到,对于所有小于或等于5的X值,Y值均为0;而对于所有大于5的X值,Y值均为1。当仅有一个预测因子(如简单逻辑回归)时,我们可以直观地看到“完全分离”的含义:
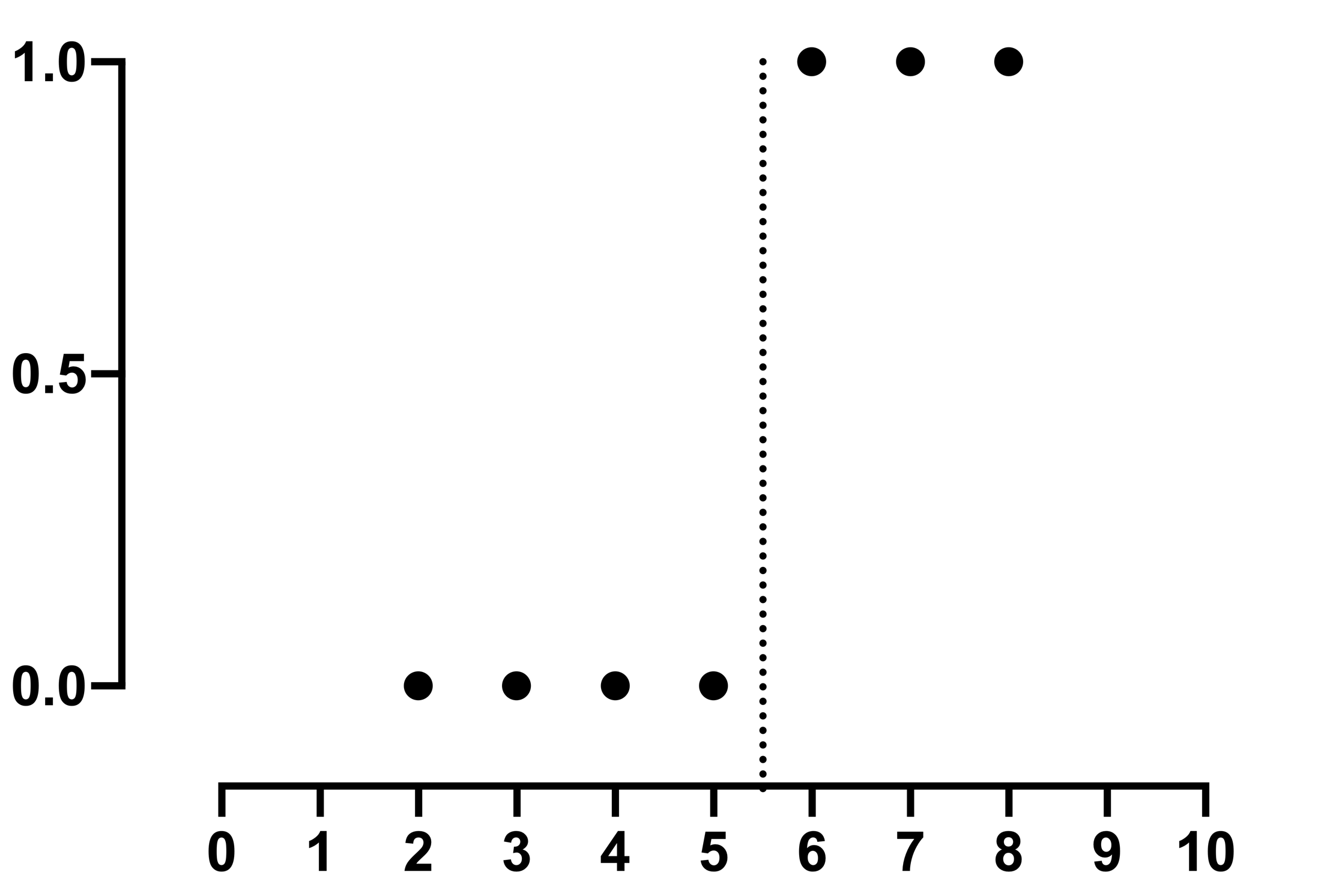
显然,可以在 X=5 和 X=6 之间画一条垂直线,该线左侧的所有点 Y 值均为 0,右侧的所有点 Y 值均为 1。因此,根据 X 值很容易预测结果。 但 S 形逻辑曲线无法胜任这一任务,因为数据无法提供任何线索来确定该曲线在 5 和 6 之间的具体位置。如果 X=5.5,预测概率是多少?
准完全分离
准完全分离是与完全分离密切相关的一个问题。当一个预测因子(或预测因子的线性组合)除了在某个特定值或点上之外,都能正确分类结果时,就会发生准完全分离。让我们再次通过一些数据来更好地理解这个问题:
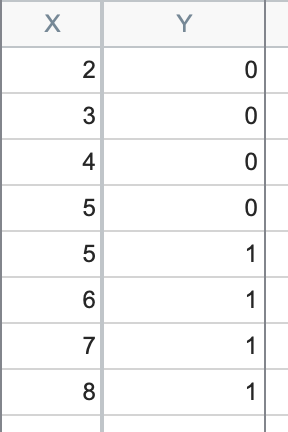
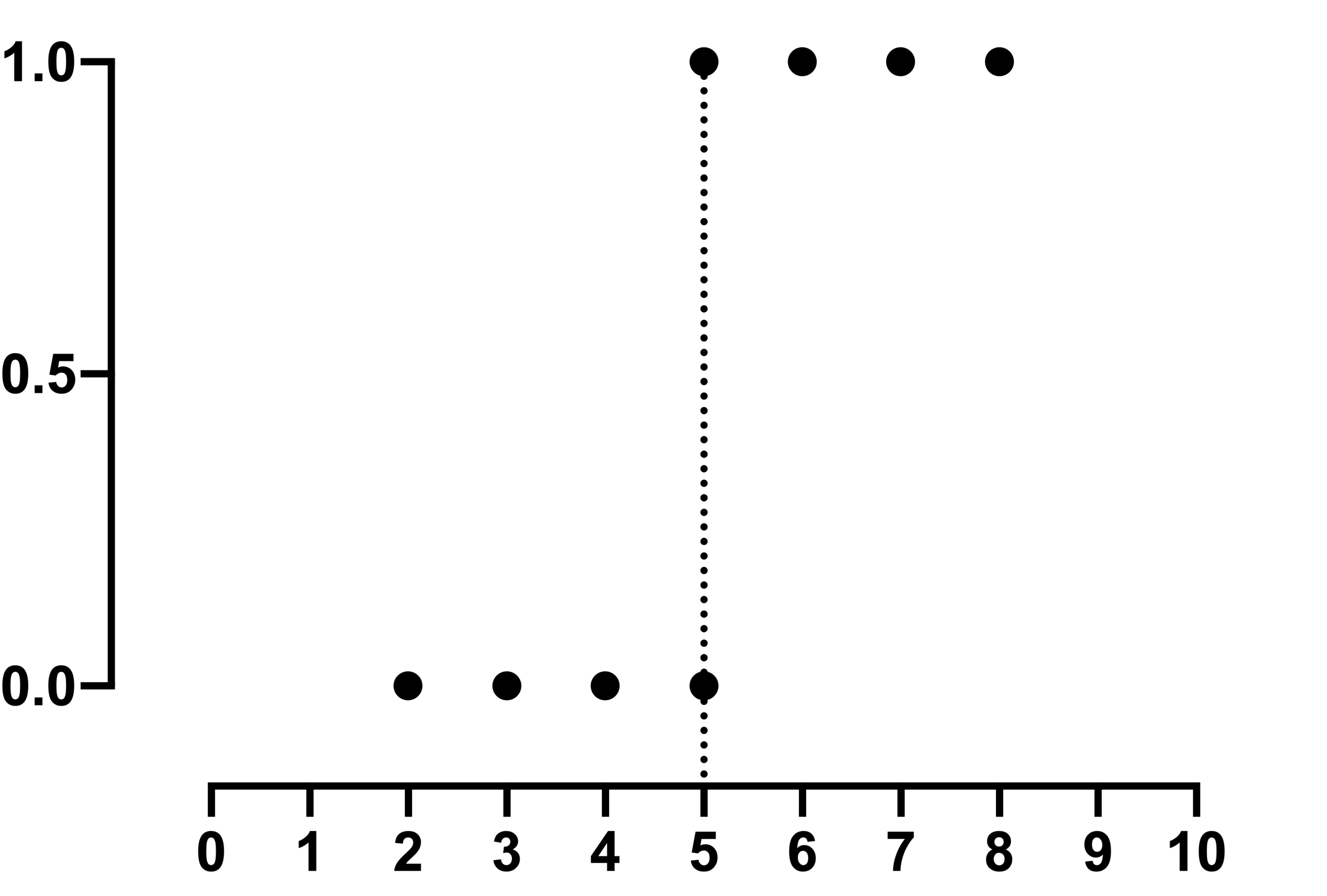
现在您可以看到,对于所有小于 5 的 X 值,Y 值均为 0;而对于所有大于 5 的 X 值,Y 值均为 1。然而,当 X=5 时,我们同时存在 Y=0 和 Y=1 的情况。再次,无法最大化似然函数,因此无法确定参数的最佳拟合估计值。
最后,如果所有 X 值均为同一数值,Prism 将无法对数据拟合逻辑模型,也无法最大化似然函数(参见下文关于线性相关的 X 变量的说明)。
但请注意,出现此错误并不一定意味着您的实验设计或数据存在问题。这可能仅仅意味着您已识别出能够完全(或近乎完全)预测结果的 X 变量(或多个变量)!
线性相关的自变量
尝试对数据拟合逻辑模型时可能遇到的另一个问题是存在线性相关的自变量。当模型包含线性相关的预测变量时,拟合模型的算法将失败,因为似然函数的最大值不存在。为理解这一点,我们首先定义“线性相关”的含义。如果任何自变量都可以表示为其他变量的线性组合,则称这些变量具有线性相关性。 但若不进一步定义“变量的线性组合”的含义,上述解释仍不够清晰。变量的线性组合指的是给定变量集合的和,其中每个变量都乘以一个常数。通过一个例子来解释可能最为直观。假设您有三个变量:X1、X2 和 X3。现在,我们写出一个公式:
X3 = A*X1 + B*X2
如果存在任何使该表达式成立的 A 和 B 的值,那么 X3 就是 X1 和 X2 的线性组合。让我们看一些数据,使这个概念更加清晰:
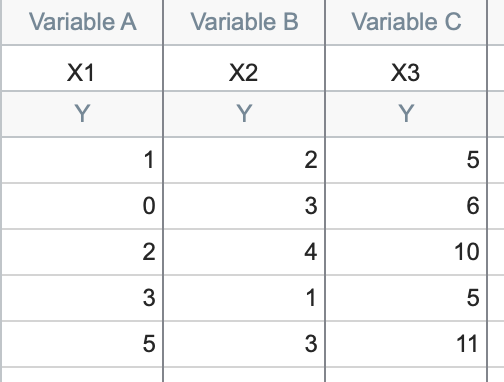
这组数据展示了我们的三个变量(变量可以是任何内容:年龄、身高、去洗手间的步数……)。对于这组数据,线性关系很容易识别:
X3 = 1*X1 + 2*X2
换句话说,在每一行中,第三个数值等于第一个数值加上第二个数值的两倍。其他线性关系可能并不那么容易发现:
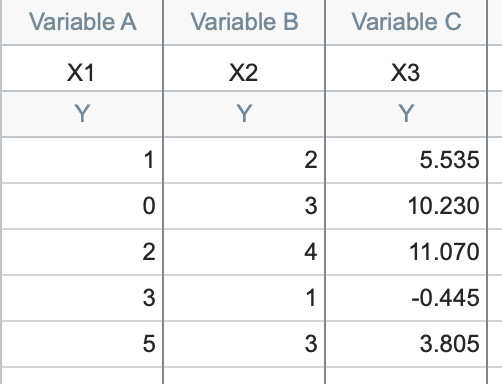
前两列的数值相同,但这里的线性关系由以下公式给出:
X3 = -1.285*X1 + 3.41*X2
线性相关问题还可能以另一种形式出现,即X列出现重复。在使用经过编码的分类预测变量时,这种情况可能会无意中发生。编码后的分类预测变量只能取有限的几个值,因此很容易理解,两个原本互不相关的分类变量为何会在每个观测值上恰好具有相同的值(如果变量之间存在某种关联,这种情况就更可能发生)。 当然,随着观测值数量的增加,这种情况偶然发生的几率会降低。
一个易于理解的变量重合示例来自足球比赛分析。假设一个变量代表“进球数”,而另一个变量代表“最终比分”。虽然本示例显而易见,但您应始终警惕模型中伪装成自变量的重复(或线性相关)变量。
若存在重复的X列、完全相关(完美相关)的X列,或具有更复杂线性关系的X列,则优化算法将无法运行。要评估此问题,请使用多元线性回归对话框中的多重共线性选项。更多详情请参阅多重共线性页面。
逻辑回归模型收敛性相关(部分)潜在问题的总结
1.0或1的样本量过少(建议每个自变量(X)至少有10行数据)
a.在极端情况下,若数据全为 0(或全为 1),则必然出现完全分离,因为算法无法区分这两种结果。
b.另一种极端情况是,当 X 变量的数量与数据行数相等或更多时。在这种情况下,无法估计模型误差。
2.您的某个 X 变量(或 X 变量的线性组合)会导致 Y 变量呈现完全分离或准完全分离。
3.您的 X 变量之间存在线性依赖度。