通过导入和粘贴特殊对话框的 "筛选器 "选项卡上的选项,可以选择导入数据文件的哪些部分。
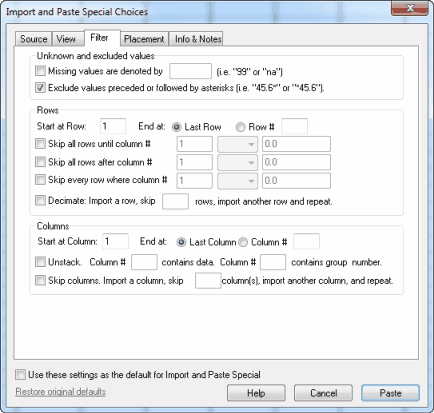
未知值和排除值
输入数据时,可以让数据表的任何部分为空。Prism 会自动计算如何处理缺失值。Prism 导入文本文件时,会自动处理缺失值。其他一些程序使用代码(如 99)来表示缺失值。如果从此类程序导入数据,请在 "筛选器 "选项卡中输入代码值。
要表示文本文件(或 Excel)中的排除值,请在该值后面打上星号。然后选中 "筛选器 "选项卡上的选项,排除星号后面的值。
选择要导入或跳过的行
首先,通过指定第一行和最后一行来选择要导入的行范围。如果要导入的文件包含 <注释>、<信息> 或 <标题> 信息(请参阅选择性粘贴),则从这些结构化信息后的第一行开始计算行数。行 "1 "是包含数据的第一行,而不是文件中的第一行。
然后,选择要跳过的行。筛选器的工作原理是检查指定列是否符合你指定的标准。您可以应用三种筛选器的任意组合:
•在满足标准之前跳过所有行
•满足标准后跳过所有行
•跳过符合标准的每一行。
定义标准时,可以使用原始文件中的任何列。您不受限制,可以使用您选择导入的列。通过检查列中每一行的值是否小于或等于 (<=)、小于 (<)、等于 (=)、大于 (>)、大于或等于 (>=) 或不等于 (<>) 您输入的值进行比较。无法定义比较两列中的值的标准,只能比较一列中的值和您在对话框中输入的值。
降维
如果数据文件很大,可以在导入时对数据进行 "十进制"。"十进制 "的字面意思是每十行数据保留一行,但您可以告诉Prism 在导入的行之间跳过任意行数。它导入一行,跳过你指定的行数,然后读取另一行。这对任何大文件都很有用,可以使Prism 文件更小,加快分析和制图速度。
列数
通过指定第一列和最后一列,选择要复制的列范围。或者选择读取一列,跳过一列或多列,然后读取另一列。
解除堆叠
有些统计程序以索引格式(有时称为堆叠格式)保存数据。每一行代表一个案例,每一列代表一个变异性。不同的组或实验条件不是由不同的列来定义的(如Prism 的组织方式),而是由分组变量来定义的。Prism 可以解堆叠索引数据。指定哪一列包含数据,哪一列包含组标识符。组标识符必须是整数(非文本),但不一定从 1 开始,也不一定是连续的。
本示例在此索引数据文件示例中,您可能只想导入第 2 列中的数据,并使用第 3 列中的值来定义两个组。
行 # |
第 1 栏 |
第 2 栏 |
第 3 栏 |
1 |
12 |
123 |
5 |
2 |
14 |
142 |
6 |
3 |
13 |
152 |
5 |
4 |
12 |
116 |
6 |
5 |
11 |
125 |
6 |
6 |
15 |
134 |
5 |
Prism 会自动重新排列数据,因此它们看起来像这样:
行 # |
第一列 |
第二列 |
1 |
123 |
142 |
2 |
152 |
116 |
3 |
134 |
125 |
标识组的列必须包含整数。最低的整数定义了组,其值将被放置在Prism 中包含插入点的列中。如果组号中有空格,Prism 将留下空白列。
|
如果使用 "选择性粘贴 "从剪贴板粘贴数据,则 "筛选器 "选项卡中的列号是相对于复制到剪贴板的数据范围而言的。本示例中,如果您将 C13-F45 单元格从 Excel 复制到剪贴板,那么Prism的 "筛选器 "选项卡中的第 1 列指的是 Excel 中 C 列的数据,即复制范围的第一列。 |
