作为常用“成对比较”功能的替代方案,Prism 允许用户在对绘制数据进行适当分析后,向图表中添加“紧凑字母显示”(CLD)。要使用此功能,只需点击工具栏“绘图”区域中的按钮(或在查看图表时,从“插入”菜单中选择“紧凑字母显示”选项)。
什么是 CLD 以及如何解读?
CLD 是一种在图表上展示多重比较结果的替代方法,它不使用带星号的括号或 P 值。取而代之的是,为每个组分配一组字母(或数字)。各组可能被分配多个不同的字母,但每个组至少会获得一个字母。 利用这些字母,可以比较任意两个组。如果两个组共享同一个字母,则表明它们之间的成对比较的 P 值不小于指定的显著性水平。换言之,假设使用了 0.05 的标准显著性水平,那么对于任何共享同一字母的两个组,可以确定这两组之间比较所计算出的 P 值不小于 0.05。
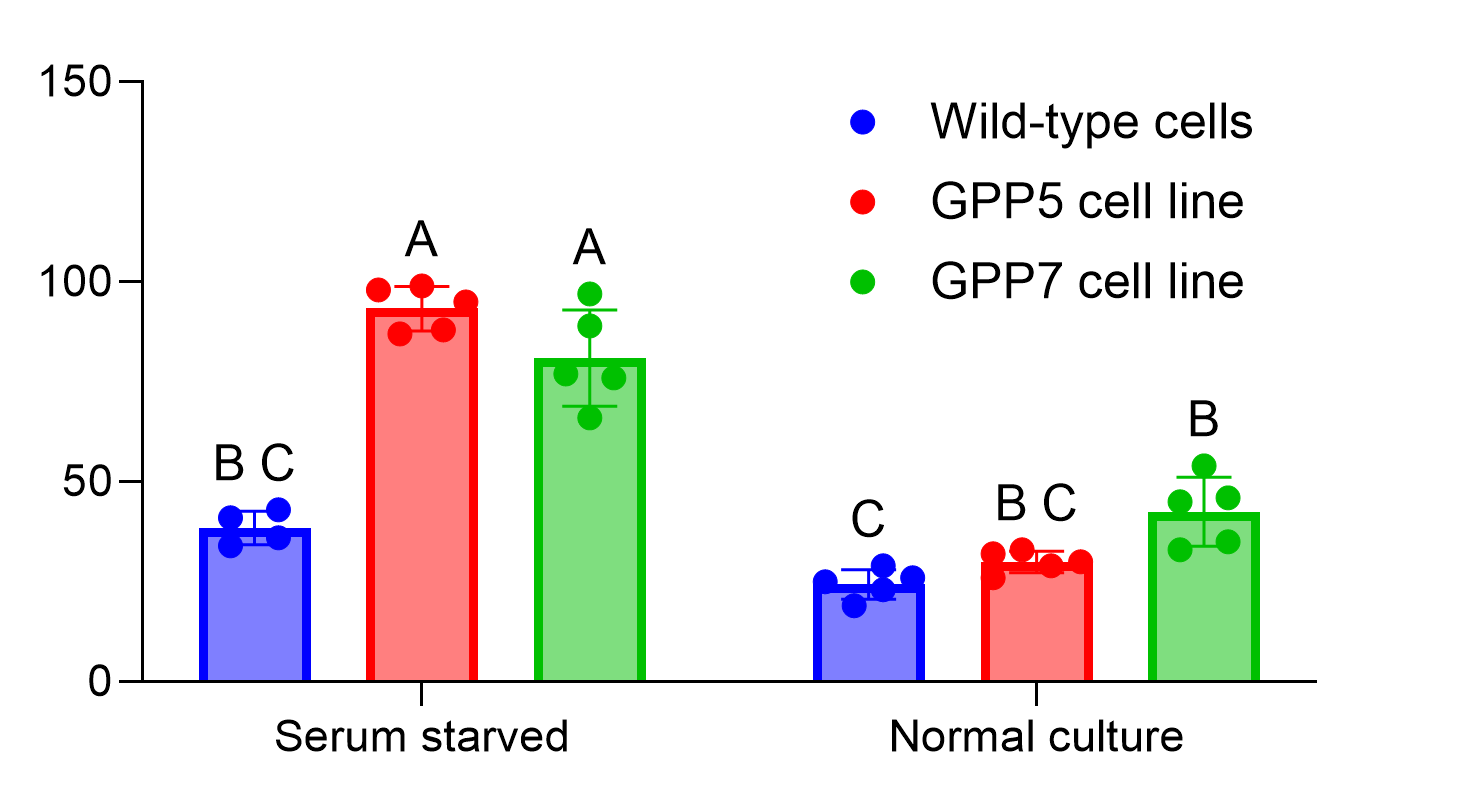
以下是成对比较的可视化及表格输出示例,以便更清晰地说明:
Tukey多重比较检验 |
预测(LS)均值差 |
差异的95.00%置信区间 |
低于阈值? |
总结 |
校正 P 值 |
|
|
|
|
|
|
血清饥饿:野生型细胞 vs. 血清饥饿:GPP5 细胞系 |
-54.90 |
-69.60 至 -40.20 |
是 |
**** |
<0.0001 |
血清饥饿:野生型细胞 vs. 血清饥饿:GPP7细胞系 |
-42.50 |
-57.20 至 -27.80 |
是 |
**** |
<0.0001 |
血清饥饿:野生型细胞 vs. 正常培养:野生型细胞 |
14.10 |
-0.5971 至 28.80 |
否 |
无统计学意义 |
0.0652 |
血清饥饿:野生型细胞 vs. 正常培养:GPP5细胞系 |
8.500 |
-6.197 至 23.20 |
否 |
ns |
0.4882 |
血清饥饿:野生型细胞 vs. 正常培养:GPP7细胞系 |
-4.100 |
-18.80 至 10.60 |
无 |
无统计学意义 |
0.9509 |
血清饥饿处理:GPP5细胞系 vs. 血清饥饿处理:GPP7细胞系 |
12.40 |
-1.457 至 26.26 |
否 |
无统计学意义 |
0.0978 |
血清饥饿处理:GPP5细胞系 vs. 正常培养:野生型细胞 |
69.00 |
55.14 至 82.86 |
是 |
**** |
<0.0001 |
血清饥饿:GPP5细胞系 vs. 正常培养:GPP5细胞系 |
63.40 |
49.54 至 77.26 |
是 |
**** |
<0.0001 |
血清饥饿:GPP5细胞系 vs. 正常培养:GPP7细胞系 |
50.80 |
36.94 至 64.66 |
是 |
**** |
<0.0001 |
血清饥饿:GPP7细胞系 vs. 正常培养:野生型细胞 |
56.60 |
42.74 至 70.46 |
是 |
**** |
<0.0001 |
血清饥饿:GPP7细胞系 vs. 正常培养:GPP5细胞系 |
51.00 |
37.14 至 64.86 |
是 |
**** |
<0.0001 |
血清饥饿:GPP7细胞系 vs. 正常培养:GPP7细胞系 |
38.40 |
24.54 至 52.26 |
是 |
**** |
<0.0001 |
正常培养:野生型细胞 vs. 正常培养:GPP5细胞系 |
-5.600 |
-19.46 至 8.257 |
否 |
ns |
0.8059 |
正常培养:野生型细胞 vs. 正常培养:GPP7细胞系 |
-18.20 |
-32.06 至 -4.343 |
是 |
** |
0.0055 |
正常培养:GPP5细胞系 vs. 正常培养:GPP7细胞系 |
-12.60 |
-26.46 至 1.257 |
否 |
无统计学意义 |
0.0894 |
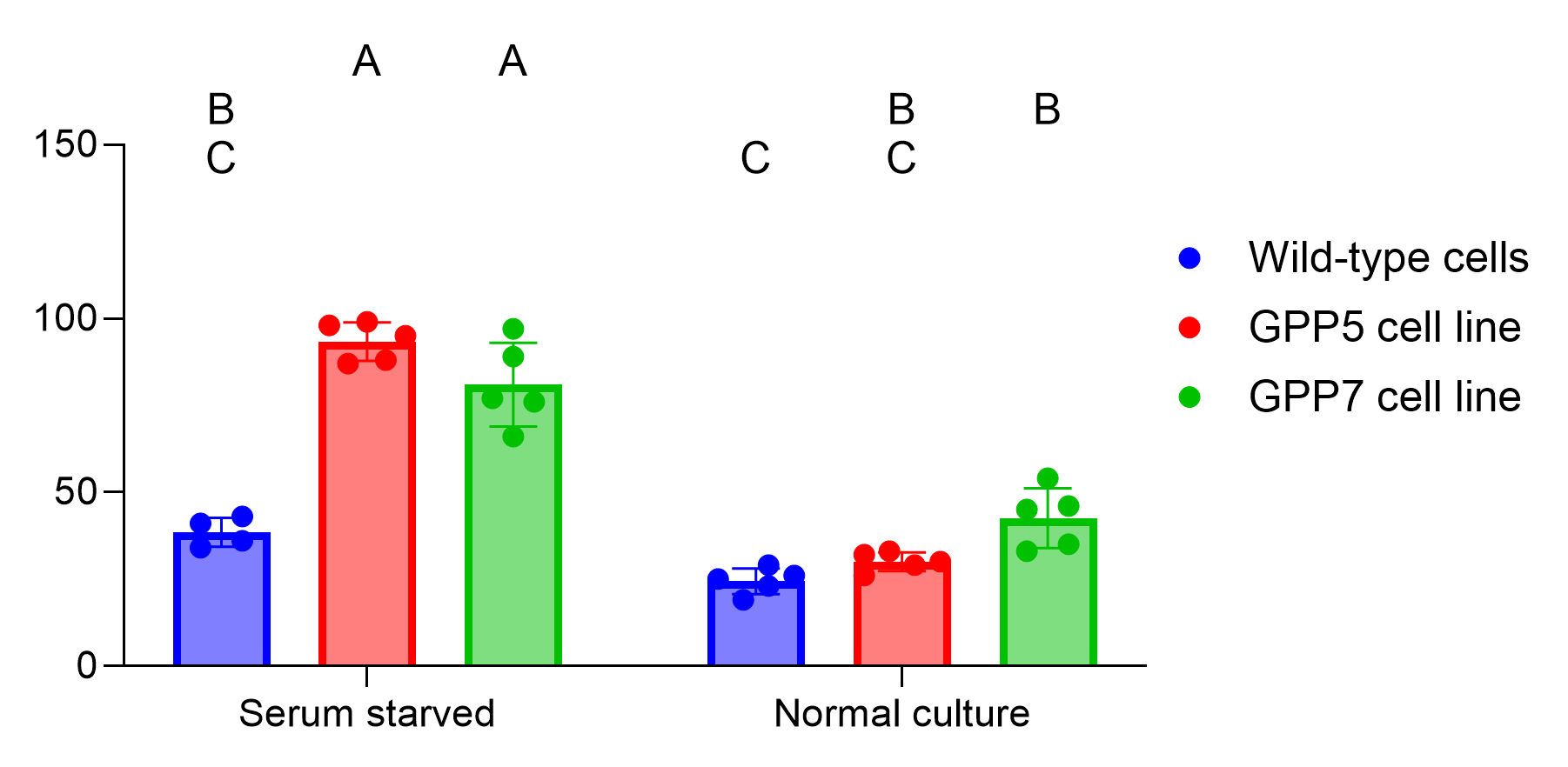
首先观察“血清饥饿:GPP5细胞系”和“血清饥饿:GPP7细胞系”这两个组。从图表中可以看到,这两个组都被分配了字母“A”。由于这两个组共享同一个字母,因此我们预期这两个组之间的成对比较所得的P值应大于显著性水平(本例中为0.05)。 查看表格,我们可以看到确实如此,该比较的校正P值为0.0978。
此外,我们可以考察“血清饥饿:野生型细胞”这一组。该组被分配了字母“B”和“C”,这意味着该组与任何包含字母“B”或“C”的其他组之间的比较,其P值应大于指定的α值(0.05)。 例如,若将其与字母标记为“C”的“正常培养:野生型细胞”组进行比较,可得校正P值为0.0652。同样地,与字母标记为“B”的“正常培养:GPP7细胞系”组比较时,对应的P值为0.9509。 然而,若与字母标记为“A”的“血清饥饿:GPP5细胞系”组进行比较,我们预期P值应小于设定的α值(因为这两个组没有共同的字母标记)。事实上,该比较的校正P值确实小于0.0001。
为何使用紧凑字母显示
如果 CLD 只是简单地显示所有多重比较的汇总结果,那为何不直接使用 Prism 内置的“成对比较”功能呢?一个主要原因是降低图表的复杂度和杂乱程度。请比较上文中使用 CLD 与使用“成对比较”功能绘制的同一张图表:
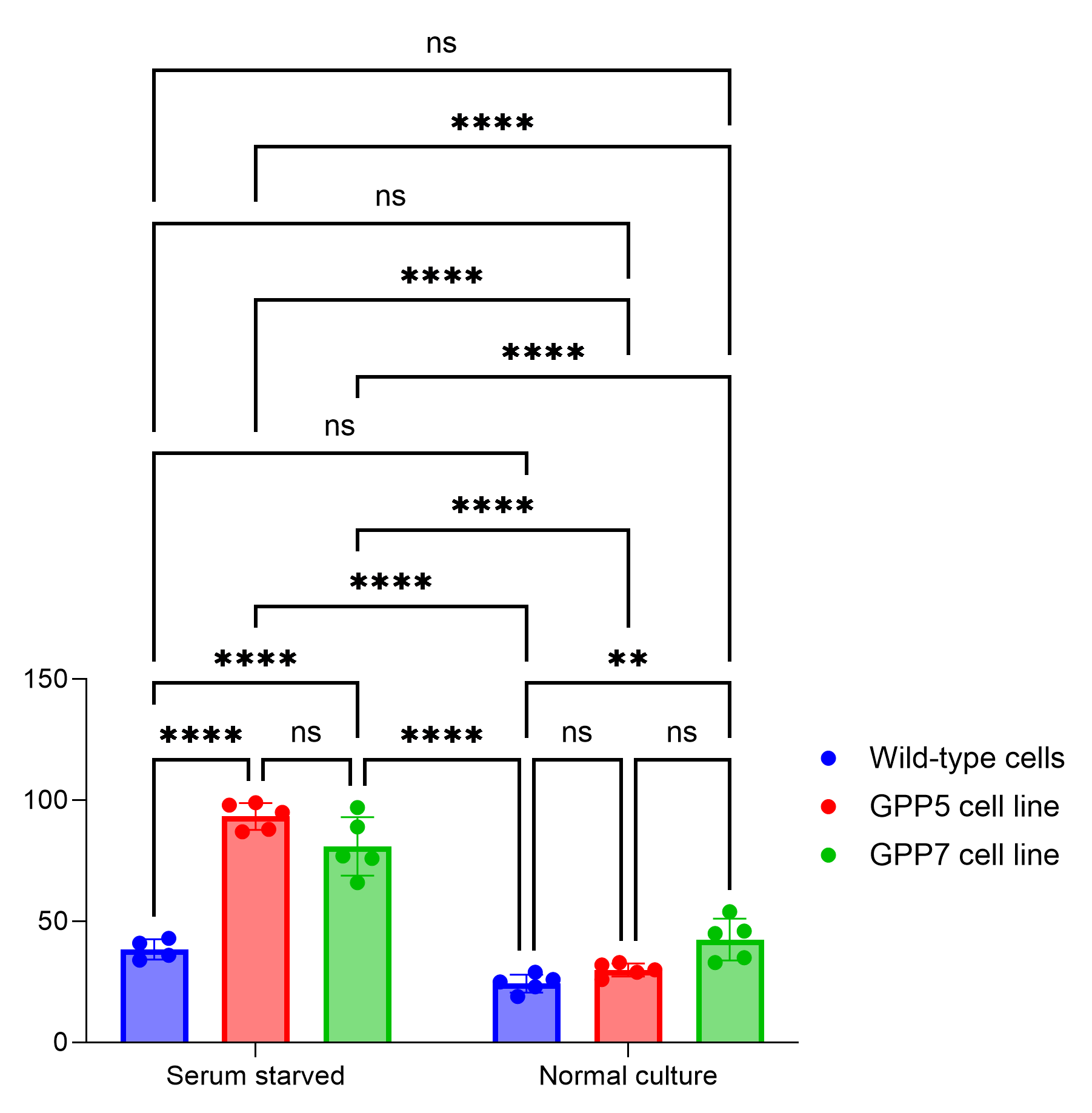
不难看出,使用 CLD 能显著减少图表上显示的内容量,从而更便于解读。但请注意,部分读者可能对 CLD 不太熟悉,因此可能需要稍作解释以确保正确解读。
哪些分析支持紧凑字母显示?
紧凑字母显示仅在比较每个组与其他所有组时才有意义。因此,CLD 可用于:
•采用“比较每列的均值(秩)与其他所有列的均值(秩)”这一多重比较方法的单因素方差分析(及其所有变体,包括配对/非配对、参数/非参数)
•采用“不考虑行和列,比较单元格均值”多重比较方法的双因素方差分析
请注意,虽然可以在 t 检验后的数据图表中添加 CLD,但不建议这样做,因为它既不如直接使用“成对比较”功能添加数值 P 值或汇总星号那样信息丰富,也不如后者直观。
“紧凑字母显示”格式对话框
在执行适当的分析(或从旧版本的 Prism 重新计算适当的分析)后,首次单击 CLD 工具栏按钮将自动将 CLD 添加到图表中。大多数情况下,您只需执行这一步即可!
不过,如果您希望自定义 CLD 的外观,再次单击工具栏按钮(或双击其中一个 CLD 字母)将打开“格式化紧凑字母显示”对话框。
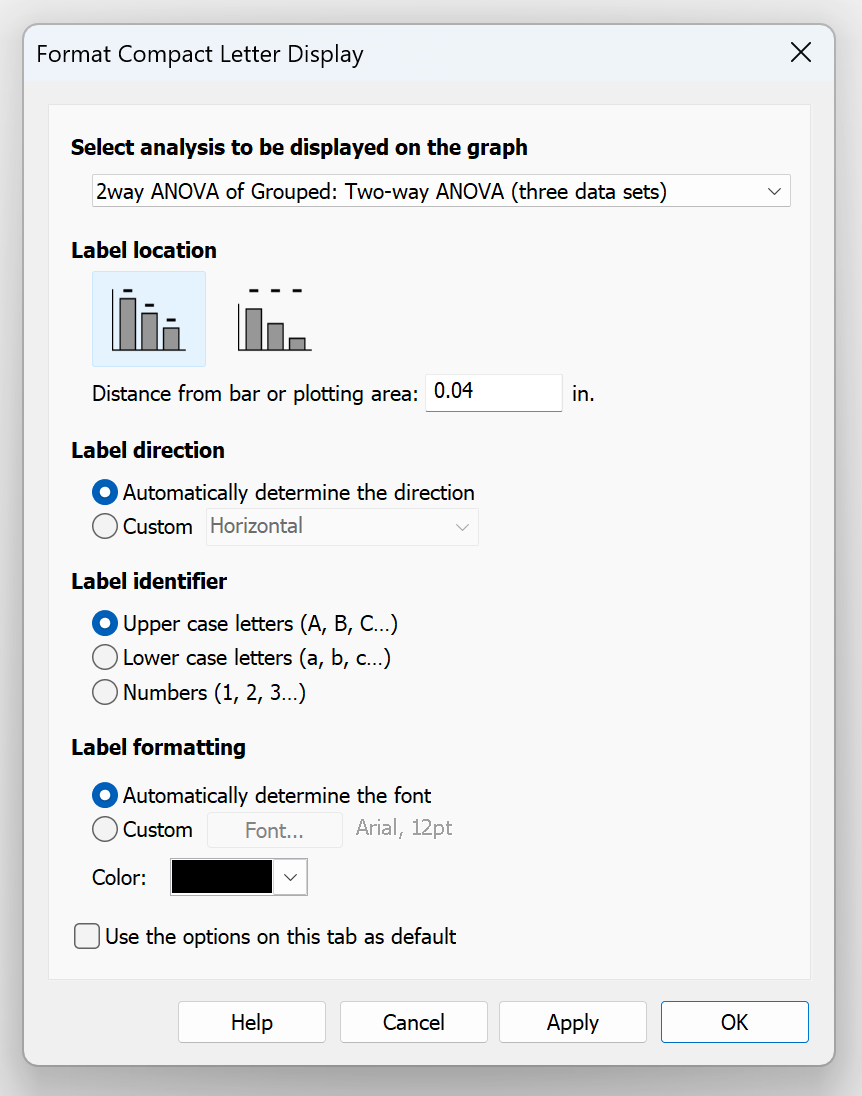
选择要在图表上显示的分析
Prism 仅能显示单个分析的 CLD。如果您对绘图数据执行了多个合适的分析(即使这种情况不太可能发生),您需要确定哪个测试包含您希望用于生成 CLD 的比较。
标签位置
此选项用于指定是否将 CLD 字母直接添加在数据上方(柱形、符号、误差线等),还是添加在图表区域之外。请注意,若选择第二种选项,标签方向将仅有一个选项(见下文)。以下是使用上述同一张图表展示的两种标签位置选项示例:
请注意,在第二种变体中,标签的排列方式使得每个字母位于相同的“高度”(或同一行)。当组数较多时,这便于快速扫描特定行,查看哪些其他组与给定组共享(或不共享)某个字母。
标签方向
这些控件允许您指定 CLD 标签的文本方向。Prism 会根据多个因素(包括组数、图表大小等)尝试自动确定方向。此外,您还可以从以下选项中手动选择标签方向:
•水平
•垂直(向上)
•垂直(向下)
•堆叠
请注意,如果您选择将标签放置在图表区域外的布局(参见上文),则唯一可用的标签方向将是“堆叠”。
标签标识符
这些控件可用于选择大写字母(A、B、C...)、小写字母(a、b、c...)或数字(1、2、3...)作为 CLD 的标签。请注意,Prism 的默认设置是使用大写字母,但小写字母也很常见。数字则很少使用。
标签格式
这些控件可用于指定 CLD 标签的字体、大小和颜色。请注意,如果选中了“自动确定字体”选项,Prism 将根据可用空间(基于组数、图表大小等)自动调整标签的大小。