在进行等效性检验之前,您首先必须界定一个您认为在科学上或临床上有意义的治疗效果范围。您必须基于科学或临床判断来设定这个范围 - 统计分析无法提供帮助。
如果观察到的治疗效果超出了这一科学或临床无差异区,那么显然无法得出两种治疗等效的结论。
如果治疗效应确实位于临床或科学无差异区内,那么您可以考察数据是否足够可靠,以得出治疗方案等效的有力结论。
使用置信区间检验等效性
下图展示了利用置信区间检验等效性的逻辑。横轴表示治疗效应的绝对值(平均反应值之间的差异)。实心圆表示观察到的效应,其位于无差异区内。水平误差条表示单侧95%置信区间,该区间显示了与数据一致的最大治疗效应(置信度为95%)。
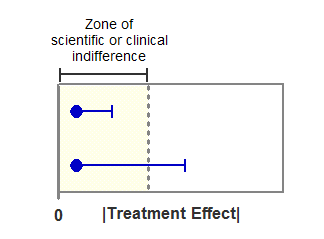
在上方的实验中,即使置信区间的边界也位于无差异区内。因此可以得出结论(95%的置信度),两种处理是等效的。
在下图所示的实验中,置信区间超出了无差异区。因此,您无法得出两种处理等效的结论。您也不能得出两种处理不等效的结论,因为观察到的处理效果位于无差异区内。面对此类数据,您根本无法对等效性做出任何结论。
使用统计假设检验进行等效性检验
通过置信区间(如上所述)来思考统计等效性相当直观。但将统计假设检验的理念应用于等效性则要复杂得多。
统计假设检验始于零假设,然后判断是否有足够证据来拒绝该零假设。当寻求差异时,零假设即认为不存在差异。 而在等效性检验中,我们寻求的是两种治疗方案等效的证据。因此,在此情境下,“零假设”并非认为两种治疗方案不等效,而是认为其差异仅略微超出科学或临床无差异区间的范围。
在上图中,将零假设定义为:真实效应等于虚线所示的效应。 接着问:如果该零假设成立,在给定样本量和变异性的情况下,观察到效应量小于或等于实际观察到的效应量的概率是多少。如果P值较小,则拒绝“不等效”的零假设,从而得出两种治疗方案等效的结论。如果P值较大,则数据与“效应量不等效”的零假设一致。
由于您只关心获得比零假设低得多的效应的概率(如果差异更大,您就不会进行该检验),因此使用单尾P值。
上图以效应的绝对值作横轴。若直接绘制治疗效应本身,则会出现两条以0点为对称中心的虚线,一条表示正向治疗效应,另一条表示负向治疗效应。此时将有两个不同的零假设,每个均通过单侧检验进行检验。这种方法被称为“双单侧检验程序”(1, 2)。
这两种方法是等效的
当然,采用95%置信区间法(使用单侧95%置信区间)与假设检验法(采用单侧0.05显著性阈值)是完全等价的,因此得出的结论始终一致。在我看来,置信区间法要直观易懂得多。
使用 Prism 进行等效性检验
Prism 没有内置的等效性检验功能。但您可以使用 Prism 进行计算:
1.使用t检验比较两组数据(根据实验设计选择配对t检验或非配对t检验)。
2.勾选生成90%置信区间的选项。没错,是90%,不是95%。
3.如果 90% 置信区间的整个范围都位于您定义的无差异区间内,那么您可以以 95% 的置信度得出结论:两种治疗方案是等效的。
|
对从90%置信区间到95%确定性结论的转换感到困惑吗?很好。这说明您在认真听讲。这确实令人困惑! |

参考文献
1. D.J. Schuirmann, 《评估平均生物利用度等效性的“两个单侧检验法”与“功效法”的比较》,《药代动力学与药效动力学杂志》,115: 1567, 1987.
2. S. Wellek, 《等效性统计假设检验》,Chapman and Hall/CRCm出版社,2010年,ISBN: 978-1439808184。