主成分回归(PCR)是主成分分析(PCA)与多元线性回归(MLR)的结合。通常,通过PCA进行降维的目标正是PCR,而Prism软件允许用户在PCA的选项中执行PCR。当选择将PCR作为PCA的一部分执行时,PCA的结果中除了原有的PCA结果外,还会额外包含一个回归结果标签页。
简而言之,先运行PCA并选取若干主成分,然后将这些选定主成分的得分作为自变量(预测变量)进行MLR分析。您选定的另一个变量(未包含在PCA中)则作为因变量(结果变量)。
Prism 会在后台执行额外一步操作。它不会以主成分得分的量纲报告回归系数,而是将回归系数转换回原始输入变量的量纲。
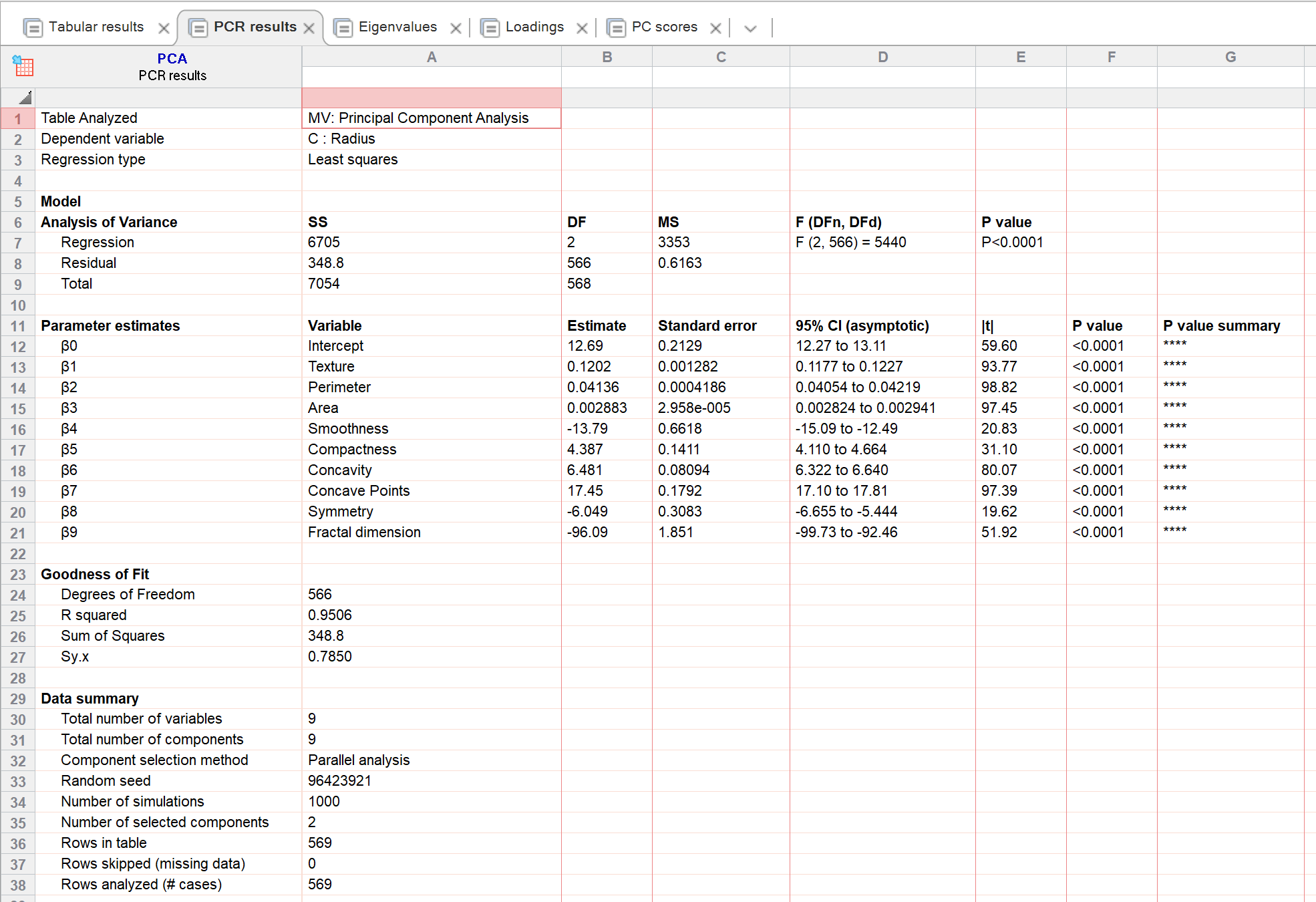
请注意,在下图显示的PCR结果中,回归模型使用了两个自由度,因为仅选取了两个主成分作为独立变量。但请注意,系数是针对全部九个独立变量加上截距显示的。这看似令人费解,但正是PCR的核心所在。本质上,MLR是基于投影到更低维度的数据进行拟合的(这听起来可能很玄妙,具体解释详见此处)。
除了使用主成分得分拟合多重线性回归(MLR)外,系数、标准误差和置信区间的解读与多重线性回归(MLR)完全一致。例如,模型为
估计响应 = β0 + β1*X1 + β2*X2 + β3*X3 + ...
请查阅关于多元线性回归的补充页面,以了解如何解读方差分析表、P值和R²。
主成分是PCR的预测变量,而非原始变量
需注意一个特殊情况。首先,我们将数据点的总数(数据表中的完整行数)记为“N”。此外,我们将选定的主成分(预测变量)的数量记为“k”。
方差分析表中的总自由度定义为 N-1。为何要减去 1?因为截距项已被拟合。回归的自由度定义为 k,残差的自由度定义为 N-k-1。简单验证可知,回归自由度与残差自由度的和等于总自由度:
dfreg + dfres = k + (N-k-1) = N - 1 = dftotal
在“拟合优度”部分,自由度定义为分析的总行数(N)减去参数数。参数数与预测因子数不同,因为该模型包含截距项。这意味着参数总数等于预测因子数加1,即 k+1。因此,要计算“拟合优度”部分的自由度,最终公式为:
dfgof = N - (k+1) = N - k - 1
本示例包含569行数据,结果表显示了10个参数的估计值(9个自变量加上截距项)。然而,回归部分仅有2个自由度,残差部分则有566个自由度。这是因为回归模型实际上仅将两个主成分视为自变量(或独立变量)。 因此,自由度计算为 569 - 3 = 566(3 是因为模型拟合了两个主成分加上截距)。这就是 PCR 的“魔力”。PCA 过程将独立变量的数量减少到较少的主成分数量(且不会丢失太多信息),从而为分析“提供了”更多的自由度。
PCR 数据摘要
与PCA表格结果的数据摘要类似,PCR结果也包含一个“数据摘要”部分。该部分提供了原始变量数量、主成分选择方法、所选成分数量(用作PCR的预测变量)以及数据表中的行数等信息。 虽然这些数值在PCA和PCR的数据摘要中是相同的,但需要注意的是,最后两行关于“跳过行数(缺失数据)”和“分析行数(案例数)”的信息在PCR中可能与PCA不同。
请注意,要执行PCR,必须从输入数据表中选择一个变量作为回归的因变量(结果变量),且该变量不能作为PCA的自变量。随后,对所选变量执行PCA。如果这些变量中存在缺失值(或被排除),PCA计算过程中将跳过这些行。 随后,将使用计算出的主成分(PCs)和指定的响应(结果、因变量)变量进行PCR。对于PCR,Prism会检查定义主成分的变量或响应变量中是否存在缺失值(或被排除),并跳过这些变量中任何一个存在缺失值的行。
为确保这一点极其清晰,这里提供另一种思考方式。作为PCA一部分生成的主成分,是利用指定输入变量中所有可能的数据(不包括因变量)来定义的。随后,这些主成分将用于与指定因变量的回归分析。如果某行有缺失值,该行将被排除在回归分析之外,但该行上的其他值仍参与确定主成分的值。
总结:
•在PCA中因缺失值(或被排除)而被跳过的行,在基于同一数据的PCR中也会被排除
•在指定响应变量中存在缺失(或被排除)值的行,仅会在 PCR 中被排除。如果某行仅缺少响应变量的值,但其他所有输入变量均有值,则该行将用于 PCA,但在 PCR 中会被跳过
•因此,对于同一数据集,PCR中“跳过的行(缺失数据)”的数量可能比PCA更多