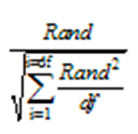随机还是伪随机?
生成真正随机数的唯一方法是通过物理随机过程,例如掷骰子或测量放射性衰变之间的间隔。Prism与所有计算机程序一样,都是通过预定义的计算来生成“随机”数。由于数列是可重现的,数学家们称这些数为“伪随机数”。
真正随机数与伪随机数之间的差异很少会造成问题。对于大多数用途而言,计算机生成的随机数已足够随机,足以用于模拟数据和测试分析方法。
Prism在计算第一个随机数时会采用当前时间,因此每次运行程序时,您都会得到一组不同的随机数序列。
来自高斯分布的随机数
Prism 采用改编自《C语言数值计算》(W. H. Press 等,第二版,剑桥大学出版社,1992年)中所述原理的程序,从高斯分布中生成随机值。函数 RAN3(定义于《C语言数值计算》中)生成均匀分布的随机数,而函数 GASDEV 将其转换为均值为零、标准偏差由您输入的高斯分布。
若选择相对误差,Prism 首先会从均值为零、标准差等于您输入的百分比误差的高斯分布中计算一个随机数。随后,它将该百分比乘以理想的 Y 值,从而得出实际值,并将其加到 Y 值上。
来自 t 分布的随机数
Prism 还可以生成来自 t 分布的随机数,其自由度 (df) 可以是任意数值。这使您能够模拟比高斯分布更宽的散布。 若自由度(df)较低,该分布范围非常宽。若自由度较高(约20以上),则几乎无法与高斯分布区分。若df=1,分布范围极宽(存在大量异常值),且与洛伦兹分布(亦称柯西分布)完全一致。Prism使用以下公式生成自由度为df的t分布随机数: