在执行Cox比例风险回归后,我们可能需要考察该模型在描述输入数据方面的表现如何。评估这种拟合优度的一个方法是,将模型估计的每个个体的风险值与输入数据中这些个体的实际生存时间进行比较。
简明版
Prism 会报告哈雷尔 C 统计量(一致性统计量)的数值及其相应的 95% 置信区间。计算 C 统计量时,会考虑所有至少有一项包含事件的观测值对(若一对观测值均被删剪,则该对不纳入计算)。 对于每对观察值,将观察时间(“T”,在表格中输入)与相对风险(“XB”,由模型确定)进行比较。在事件发生时间较短的观察值同时具有较高相对风险的配对中,该配对被视为“一致”(即模型通过赋予较高相对风险,正确识别出应具有较短生存时间的观察值)。 不符合此预期关系的配对被视为“不一致”(或在某些情况下,因观察时间或相对风险评分出现并列值而无法被识别为“一致”,详见下文“详细版本”)。
C统计量代表一致对的比例(即模型正确预测生存时间较短的观察值对所占的比例),因此其取值介于0到1之间。该值表示一种条件概率:对于任意一对观察值,模型会将更高的风险比分配给生存时间较短的那个观察值。 因此,C统计量接近1的模型表明其具有更强的区分能力,而C统计量接近0.5的模型表现仅与随机概率相当。C统计量小于0.5的模型极为罕见,通常仅因样本量极小导致的波动所致。若您看到C统计量小于0.5,很可能说明出现了问题!
C统计量的原理
对于给定的观测值,较大的相对风险(XB)值表明风险更高,因此生存时间更短。因此,如果一个观测值的XB值较高,且发生事件的经过时间比另一个观测值更短,则可认为这些观测值表现符合预期。 然而,如果某个观测值的 XB 值更高,但距离目标事件的经过时间却比另一个观测值更长,那么这些观测值可被视为表现异常。一致性(Concordance)即符合预期行为的数据对所占的比例(假设任意两个观测值之间的相对风险值不存在平局)。
另一种解读一致性的方法是将模型视为一种预测装置。当给定两组观测数据时,该模型将预测哪一组观测的生存时间更长。 完美的预测装置能正确预测每一对观测值,而真正的随机装置预计只能正确预测一半的观测值对(可将模型视为仅通过抛硬币来决定哪个观测值应具有更高相对风险的装置:我们预计其正确率约为50%)。
一致性值反映了这种行为,其取值范围必须在0到1之间。 值为1意味着模型正确预测了所有观察值对(被预测生存时间更长的观察值确实生存时间更长,被预测更早经历目标事件的观察值确实更早经历该事件)。如果模型是真正随机的,则一致性值应为0.5,这表明模型有一半概率能正确预测哪些观察值在目标事件发生前“存活”更久。
如果这种一致性概念听起来与逻辑回归中报告的拟合优度指标(ROC曲线下面积)相似,那是因为这两个概念是完全等价的。
详细版
回顾Cox比例风险模型:
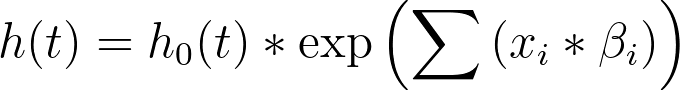
该式可重写为:
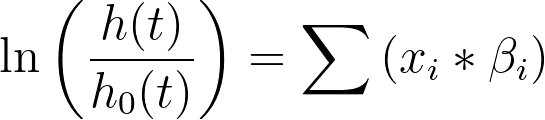
请注意,在Cox回归的语境中,“xi”表示预测变量的值(如年龄、体重、治疗组等)。
Cox 比例风险模型实际上并未对基线风险率作任何特异性假设,但可以看出线性预测因子(Σxi*βi,或简写为“XB”)与风险率(h(t))成正比。这意味着随着 XB 值的增大,风险率也会随之增大。 进而,随着危险率增加,发生目标事件的概率随之增加,因此预期生存时间将缩短。
总而言之,XB 值越大,预示着发生目标事件所需的经过时间越短。
利用计算出的参数系数 (β) 以及输入数据表中的观测事件发生时间数据,我们可以评估模型在预测这种关系方面的表现。这通过 Harrell 的 C 统计量(用于衡量一致性)来实现。
该指标由 Frank Harrell (1) 推广开来,其含义可解读如下:
•考虑输入数据表中所有可能的观测值两两组合,其中至少有一个观测值发生事件(两观测值均被删剪的组合不纳入计算)
若该对中的两个观测值均发生事件
•针对每个观测值,比较模型确定的线性预测因子(XB)与输入数据中该观测值到目标事件的实际发生时间
▪为便于记号,我们将第一个观测值的相对风险记为 XB1,第二个观测值的相对风险记为 XB2,第一个观测值的经过时间记为 T1,第二个观测值的经过时间记为 T2
•若满足以下条件,则将观测值对视为“一致”:
▪XB1 > XB2 且 T1 < T2
▪XB1 < XB2 且 T1 > T2
•若满足以下条件,则认为观察值对为“不一致”:
▪XB1 > XB2 且 T1 > T2
▪XB1 < XB2 且 T1 < T2
•当满足以下条件时,观测值对被视为“XB值相等”:
▪XB1 = XB2
•若满足以下条件,则该观测值对被视为“T值相等”:
▪T1 = T2
•若满足以下条件,则认为一组观测值在“XB和T”中并列:
▪XB1 = XB2 且 T1 = T2
若一对观测值中有一项被删剪
•对于以下定义,发生事件的观测值将具有观测时间 Te 和相对风险 XBe,而被删剪的观测值将具有观测时间 Tc 和相对风险 XBc
•若 Tc < Te,则无法确定谁先经历事件(删剪的观察对象在事件发生前已退出),因此该观察对将从计算中剔除
•若满足以下条件,则该观察值对被视为“一致”:
▪Tc ≥ Te 且 XBc < XBe
•若满足以下条件,则该观察值对被视为“不一致”:
▪Tc ≥ Te 且 XBc > XBe
•若满足以下条件,则该观测对被视为“XB 值相等”:
▪XBc = XBe
•包含一个删剪观测值和一个事件观测值的观测对不能在 T 上平局
一致性统计量的计算公式
利用上述定义,求解下列问题:
•nconcordant,一致观测对的数量
•ndiscordant,不一致对的数量
•ntied in XB,即在XB中平手的观测对数
当 XB 中不存在任何观测值对出现平局时,C 统计量的计算公式为:
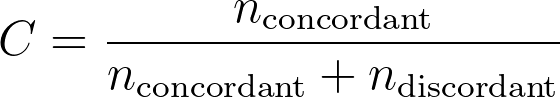
这代表模型能够正确分配适当相对风险值的观察值“比例”(相对风险值越高,生存时间应越短)。 如果对于所有观测对而言,相对风险值较大的观测值同时也是生存时间较短的观测值,那么所有观测对均为一致的,且该比例将等于 1!当存在相对风险值相等的观测对时,公式会略有不同:
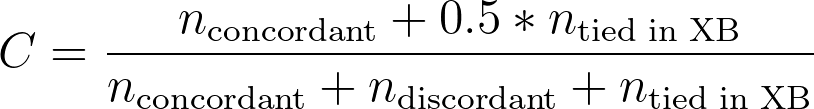
该公式与前式相似,但在分子和分母中都增加了针对平局观测值的项。回到前一节的“预测装置”示例,我们可以考虑当模型遇到线性预测因子(XB)相等的观测值时会发生什么。在这种情况下,预测装置无法判断哪个观测值的生存时间更长,因此它只能抛硬币来做出决定。 我们预计抛硬币的正确率约为50%,这就是为什么在上式分子中,XB中平局的观测对数量乘以0.5。因此,在这种情况下,C统计量仍然代表模型能够正确分配适当相对风险值的观测比例。
参考文献
1.Harrell FE, Califf RM, Pryor DB, Lee KL, Rosati RA. 医学检测效益的评估。《美国医学会杂志》。1982;247:2543–46.