P值与α值的含义回顾
解读单个P值的方法很简单。以比较两个均值为例。假设零假设成立,P值即仅由随机选择样本这一因素,导致样本均值(或相关性、关联性等)出现至少与研究中观察到的差异同样大的概率。
α是一个预先设定的阈值。若P值小于α,则认为该比较“统计学显著”。若将α设为5%,且零假设成立,则存在5%的概率,即通过随机选择受试者,导致研究者根据样本间的差异错误地推断出总体中存在某种治疗效应
多重比较
许多科学研究会检验多个假设。有些研究可能产生数百甚至数千次比较。
解读多个 P 值颇具挑战。若对若干独立的零假设进行检验,且每项比较均采用 0.05 的阈值,则获得至少一个“统计学显著”结果的概率将超过 5%(即使所有零假设均为真)。下图展示了这一问题。 至少出现一次“显著”比较的概率,是根据X轴上的比较次数(N)通过以下公式计算得出的:100(1.00 - 0.95N)。
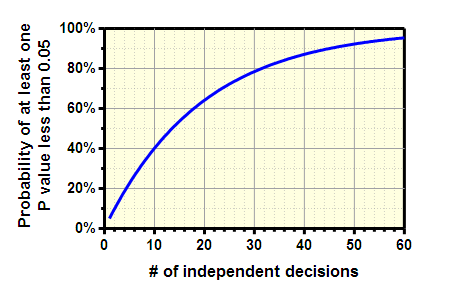
请记住那个“不祥”的数字13。如果您进行13次独立比较,仅凭偶然性,获得至少一个“显著”P值(<0.05)的概率就约为50%。
上图(及其生成公式)假设各项比较是相互独立的。换言之,它假设某一项比较获得小P值的概率与其他任何一项比较获得小P值的概率之间没有关联。如果各项比较不独立,那么实际上根本无法计算出图中所示的概率。
示例
让我们来看一个示例。您比较对照组和处理组动物,并测量血浆中三种不同酶的水平。您分别针对每种酶进行三次独立的t检验,并采用传统的α=0.05阈值来判定每个P值是否统计学显著。即使处理实际上没有任何作用,您的t检验中仍有一项或多项有14%的概率会被判定为“统计学显著”。
如果您通过10次t检验比较10种不同的酶水平,即使治疗实际上毫无作用,仅凭偶然性获得至少一个“显著”P值的可能性也是40%。最后,试想您对100种不同的酶、10个时间点以及12种预处理进行检验…… 如果您不进行多重比较校正,那么几乎可以肯定会发现其中一些结果是“显著”的,即使实际上所有零假设都是成立的。
您只能对已知的比较进行校正
在阅读研究时,只有当您知道研究者进行的所有比较时,才能对多重比较进行校正。如果他们只报告“显著”差异,而未报告比较的总数,就无法正确评估结果。理想情况下,所有分析都应在收集数据前规划好,并且都应予以报告。
了解更多
多重比较是一个重大问题,影响着几乎所有统计结果的解读。可参阅Berry的综述(1)(下文摘录)或《直观生物统计学》(2)的第22章和第23章以了解更多信息。
“大多数科学家对多重性问题浑然不觉。然而,这类问题无处不在。在各种形式中,多重性存在于每一项统计应用中。它们可能显而易见,也可能隐而不显。即使显而易见,识别它们也仅仅是艰难推断过程中的第一步。多重性问题是我们统计学家面临的最棘手难题,它们威胁着每一项统计结论的有效性。” (1)
1.Berry, D. A. (2007). 多重性这一既棘手又无处不在的问题。《药学统计学》,6,155-160
2. Motulsky, H.J. (2010). 《直观生物统计学》,第3版。牛津大学出版社。ISBN=978-0-19-994664-8。