线性回归的工作原理是拟合一个模型,利用该模型,在给定 X 的值时,可以确定 Y 的实际值。该模型揭示了这两个变量之间的关系,并回答了这样一个问题:当 X 发生变化时,Y 的值会发生多大变化?换句话说,如果使用一个能很好地描述数据的线性回归模型,仅凭预测变量的值,就能相当准确地预测因变量的值。 相比之下,逻辑回归则是在已知预测变量值的情况下,对观察到成功结果的概率进行建模。以下数据为例:
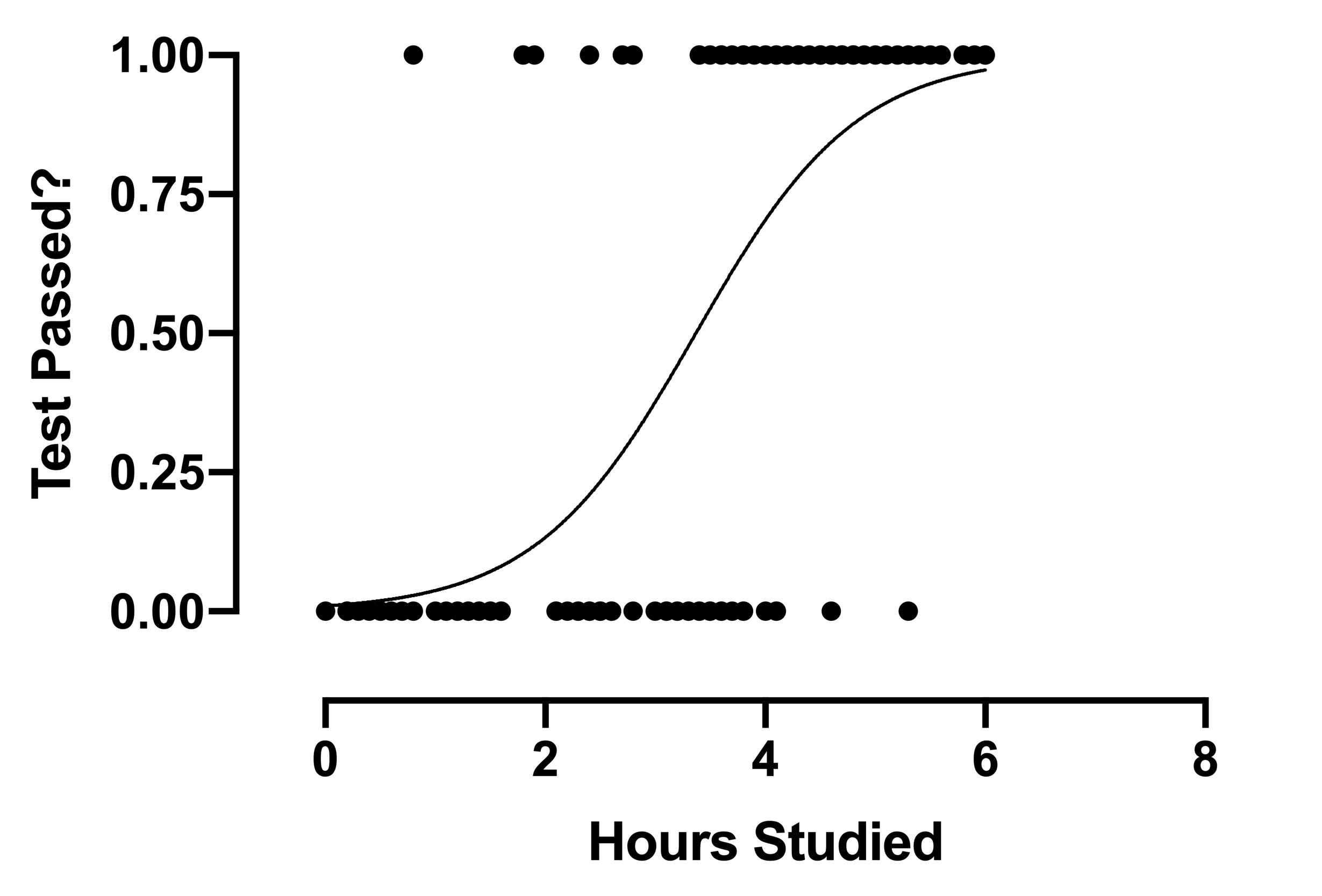
在此图中,所有数据点取值为 0(失败)或 1(通过)。逻辑回归拟合线是一条 S 形曲线,它将成功概率建模为学习时长的函数。在这个例子中,教师会很高兴地发现,学习 4 小时的学生中很少有人考试不及格。事实上,对于学习了 4 小时的学生,模型预测其通过概率约为 70%。
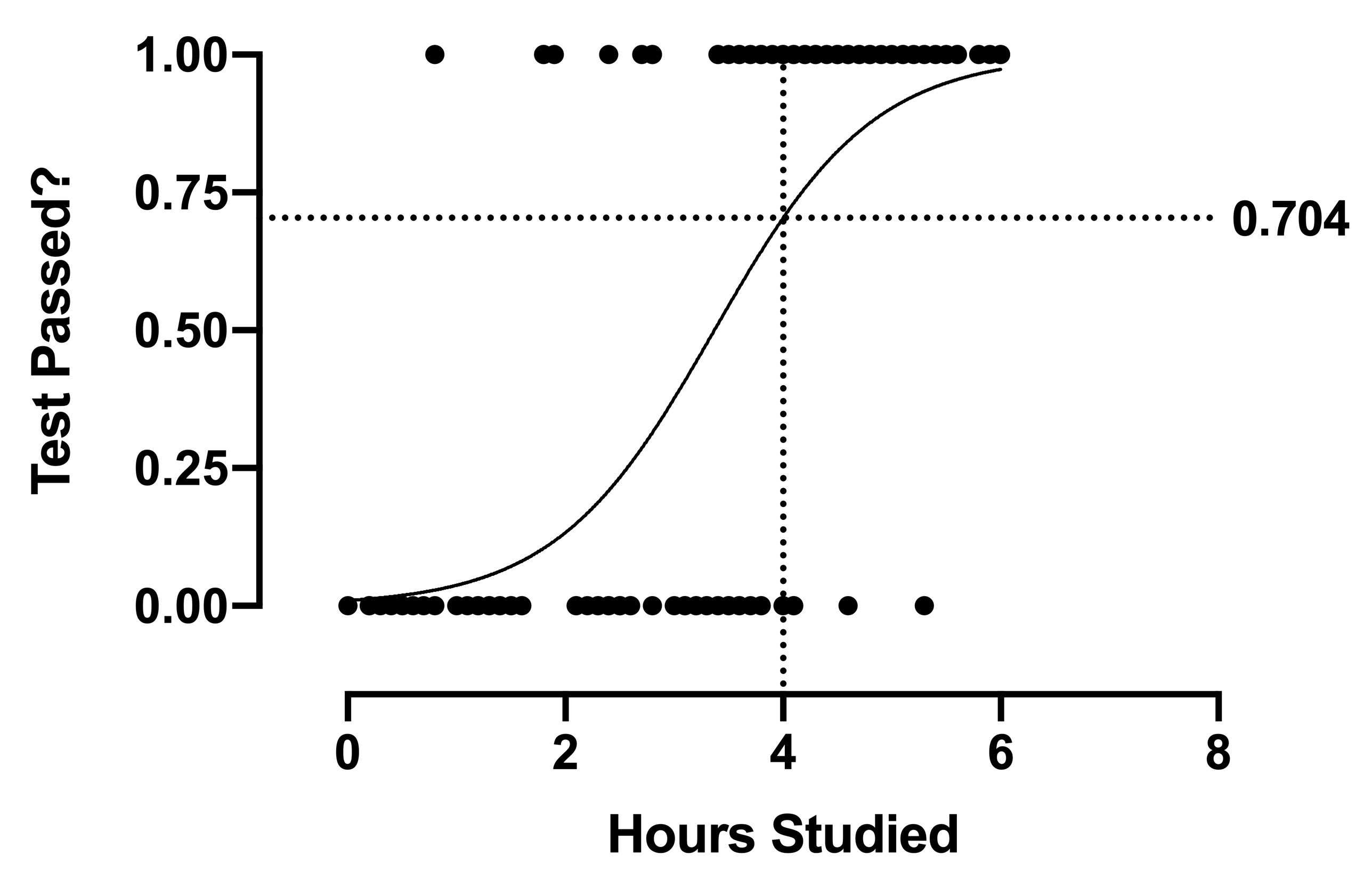
S 形曲线是逻辑斯蒂函数估计概率方式的副产品。请注意,概率的取值范围限定在 0 到 1 之间,这合乎逻辑:事件发生的概率不可能为“负数”,而概率大于 100% 也没有意义。因此,S 形曲线的上下界也受这些值的限制。 但这意味着 - 与线性回归不同 - 我们从模型中获得的数值并不能直接估计我们预期观察到的值。 当 X = 4 时,模型的预测值为 0.704。然而,对于任何在 X = 4 处进行的观测,结果只会是 0 或 1;观测值绝不会是 0.704。该模型仅仅告诉我们,在 X = 4 时,约 70% 的结果预期为 1。这是理解逻辑回归的关键点。
如果我们将逻辑回归模型与线性回归模型应用于同一数据集进行比较,便会很快明白为何简单的线性回归模型根本不适用于此类数据。
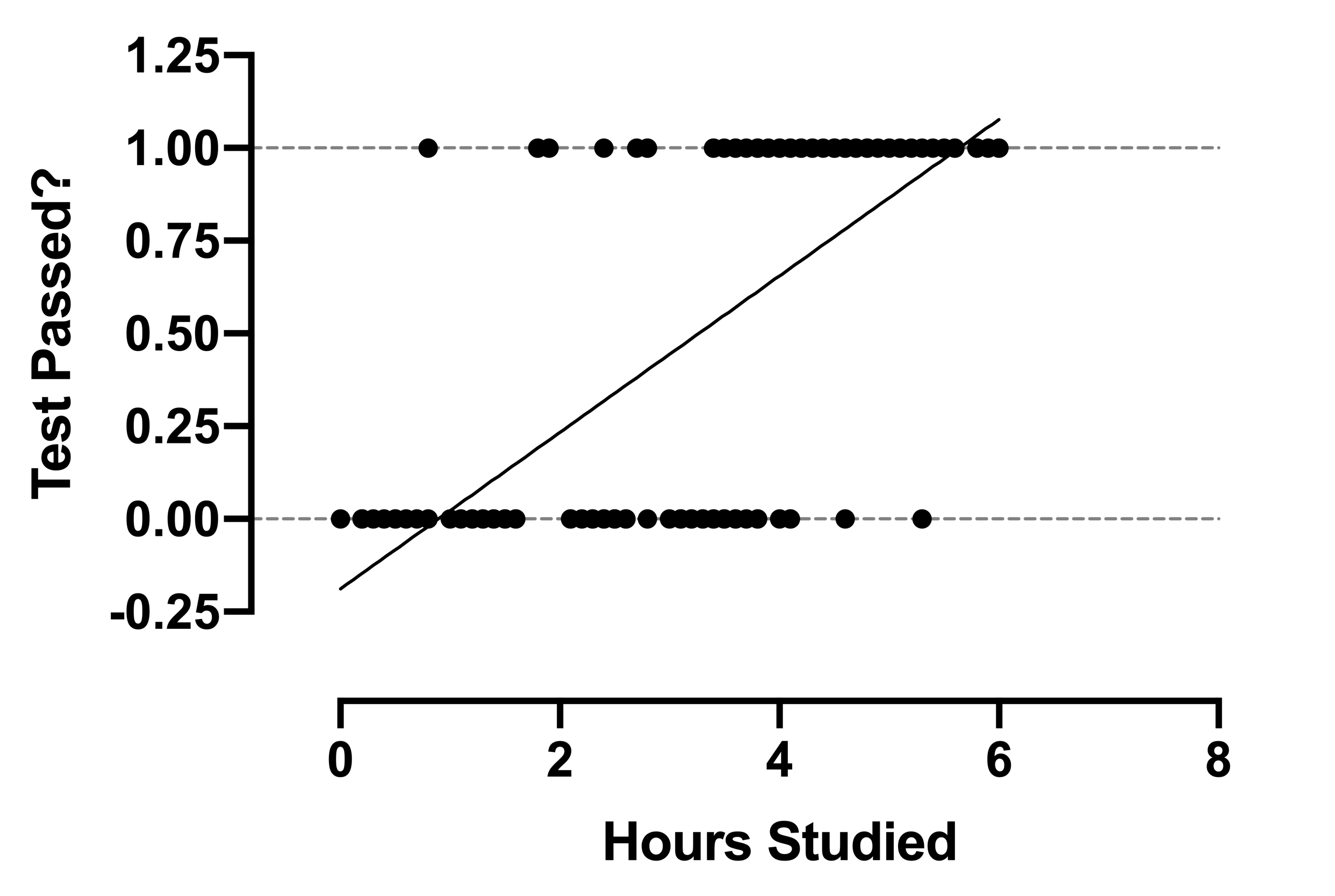
我们的数据仍然是0和1,但与逻辑回归模型不同,线性模型并非预测成功的概率。相反,它预测的值可能小于0或大于1。例如,该模型预测学习时间少于约0.9小时的学生,其通过考试的估计值为负值。 在某些情况下,线性模型可用于二元自变量以进行简单的分类。然而,这些方法无法提供系数的可解释性、显著性检验和置信区间。对于此类结果(当因变量为二元时),请使用逻辑回归。