当将一个分类型变量作为预测变量纳入回归模型时,Prism 会自动使用“虚拟编码”对该变量进行编码。此过程会在后台生成若干个新变量,其数量等于原始分类型变量的水平数减一。 换言之,如果一个分类预测变量有 5 个独特水平(例如 A、B、C、D 和 E),虚拟编码将生成 4 个新变量。 如果一个分类预测变量只有两个独特水平(例如 Male 和 Female),虚拟编码将只生成一个新变量。通过这种方式,除一个水平外,分类预测变量的每个水平都会获得一个用于回归分析的新变量。此外,还会为这些新变量中的每一个计算一个 β 系数。
但这些β系数代表什么?而那个未生成新变量的水平又如何?这两个问题都与分类预测变量“参考水平”概念有关。
什么是参考水平
分类预测变量的参考水平通常被视为该变量所观察到的“基线”或“通常”值。在虚拟编码过程中,参考水平的变量会被省略,因为它对每个观测值都仅包含“0”。相反,参考水平被用作解读生成的回归模型的一种手段。让我们通过一个例子来说明这一点:
假设有一个模型包含分类预测变量“性别”,其取值为“男性”和“女性”。如果“男性”是我们的参考水平,那么预测模型将包含“女性”的β系数,但不会包含“男性”的β系数。 在此情况下,“女性”的β系数告诉我们,在其他所有变量保持不变的情况下,男性与女性之间结果变量的对数几率预计会发生多大变化。换言之,如果“女性”的β系数为2.513,则(在其他所有变量保持不变的情况下),预计女性的结果变量对数几率比男性高2.513倍。
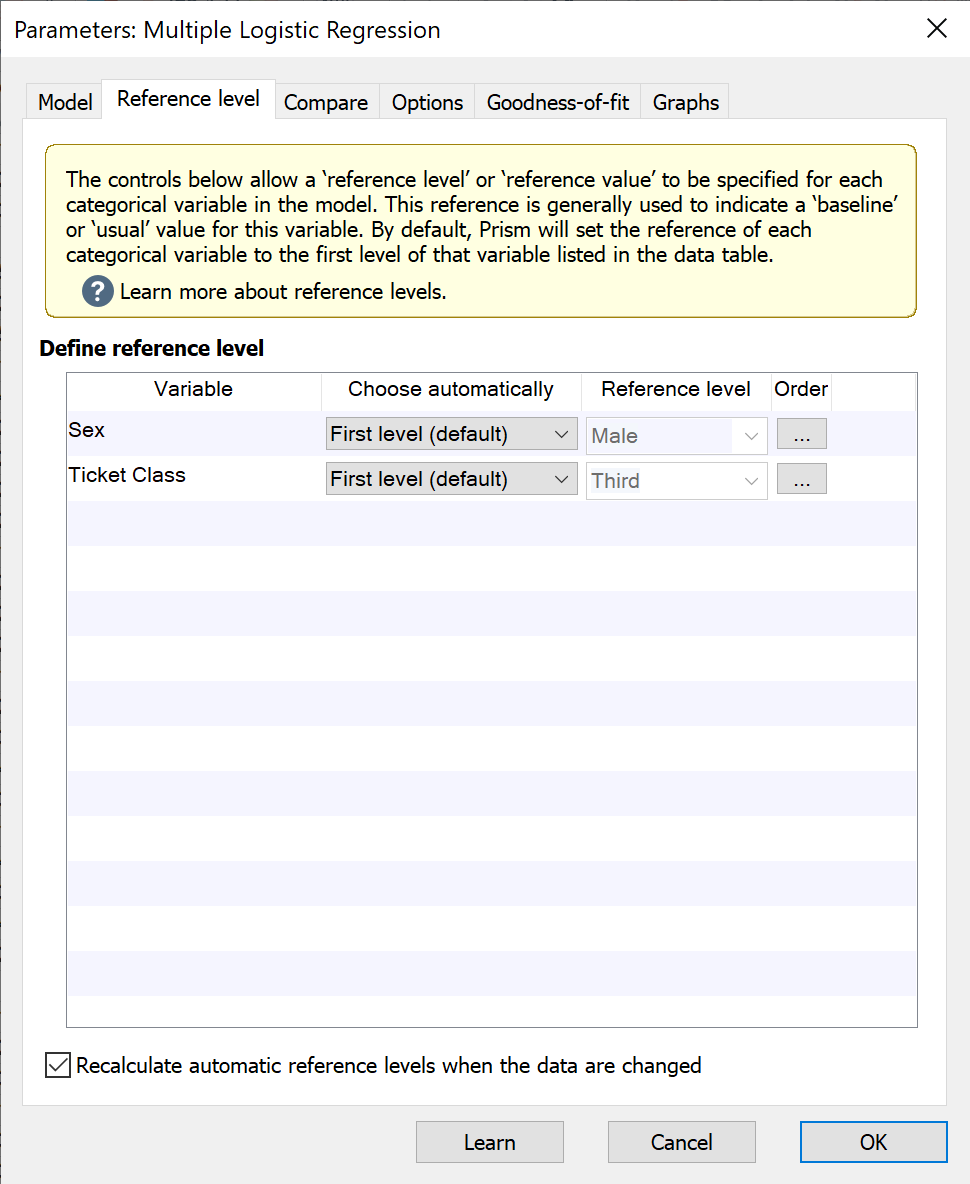
如何指定参考水平
在“参考水平”选项卡中,回归模型中包含的每个分类预测变量都会列在“定义参考水平”下。对于每个变量,您可以选择自动定义参考水平或手动定义水平。Prism 提供了多种基于数据表中的数据自动指定参考水平的方法。这些方法包括:
•第一层(默认)。这将选择数据表中该变量的第一层。请注意,如果数据表中行顺序发生变化,该参考层级也可能随之改变!
•最后一个水平。这将选择数据表中该变量的最后一个水平。请注意,如果数据表中行顺序发生变化,该参考水平也可能随之改变!
•最频繁水平。若希望回归系数能提供罕见水平相对于常见水平的信息,建议使用此选项。请注意,更改数据表中行的顺序不会导致此参考水平改变。但添加或删除数据可能会导致参考水平改变(因各水平的频率发生变化)
•最不频繁水平。这将确定变量中哪个水平最频繁,并将其选为参考水平。请注意,更改数据表中行的顺序不会导致此参考水平发生变化。但是,添加或删除数据可能会导致参考水平发生变化(通过改变每个水平的频率)
对于上述每种自动方法,数据的某些变更(组织结构调整或数据的增删)可能会导致指定的参考级别发生变化。但是,如果您希望 Prism 自动确定参考级别,同时防止其随数据变化而改变,可以使用复选框“当数据发生变化时重新计算自动参考级别”。
最后,您还可以通过在第一个下拉菜单中选择“自定义…”,并在第二个下拉菜单中选择所需级别,来指定自定义参考级别。
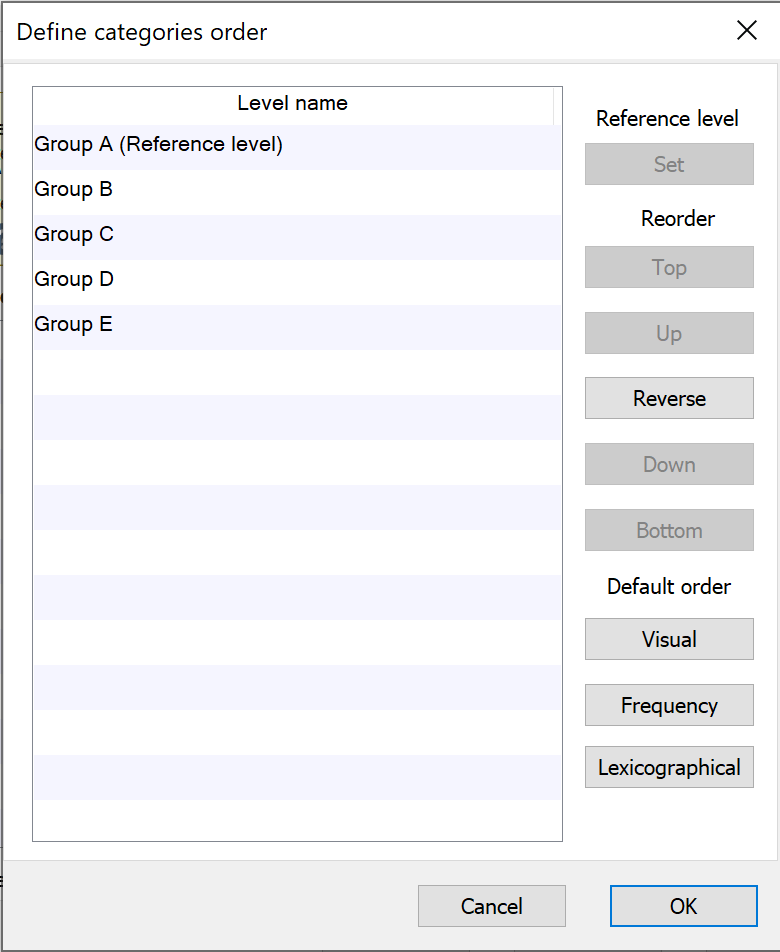
更改结果中分类变量水平的顺序
在生成回归分析的结果输出时,Prism 会按数据表中的顺序显示分类预测变量的水平。但出于展示或发表的目的,有时可能需要更改回归模型中一个或多个特定分类预测变量的水平顺序。 “定义参考水平”部分中的“顺序”按钮允许您分别自定义每个分类变量的水平顺序。“定义类别顺序”子菜单中的控件允许您:
•将分类变量的参考水平设为当前选定的水平
•手动重新排序分类水平(“顶部”、“向上”、“反向”、“向下”和“底部”控件)
•使用三种默认方法之一重新排序:
o视觉顺序:数据表中层级首次出现的顺序
o频率:频率较高的水平在排序中靠前
o字典顺序:按字典顺序排列。类似于字母顺序,但请注意,名为“a100”的水平会排在“a90”之前,因为“1”在“9”之前。此顺序不考虑“100”这个数字整体大于“90”这个数字的事实
如果输入数据发生变化,参考水平会如何变化?
默认情况下,分类变量的参考级别被选定为数据表中该变量的第一个级别。Prism 还提供其他自动选项,包括“最后一个级别”、“最频繁级别”和“最不频繁级别”。但是,如果输入数据发生变化(或向输入数据表中添加了额外数据),其中一些自动选项也可能随之改变。 若要确保在输入数据发生变更或添加新数据时,指定的参考水平保持不变,请取消勾选“数据变更时重新计算自动参考水平”旁边的复选框,或通过相应的下拉菜单将各个参考水平设置为“自定义...”。